Who Owns Who?
(Inverting the PathEngine ownership graph)
Designing an API with creation and destruction of objects can be tricky, particularly if the objects have dependency relationships.
How do we ensure that constructed API objects get destroyed at the appropriate time (and are not 'leaked')? How do we prevent code from attempting to access objects after destruction? And how do we do all this in situations where some objects depend on the existence of other objects?
In this post I talk about how I approached this in PathEngine (a pathfinding library, in C++).
When I first designed the PathEngine API, I chose an approach based on larger objects each owning a set of smaller 'contained' objects. That kind of worked out, but it turns out there's another, much better way to do this. And so it was that I recently found myself going through the SDK and turning the whole thing upside down.
Objects on a ground mesh
The ownership issue first came up with PathEngine in the context of objects placed on a 'ground mesh' (a mesh representation of a set of ground surfaces).
Let's look at some of the concrete objects involved:
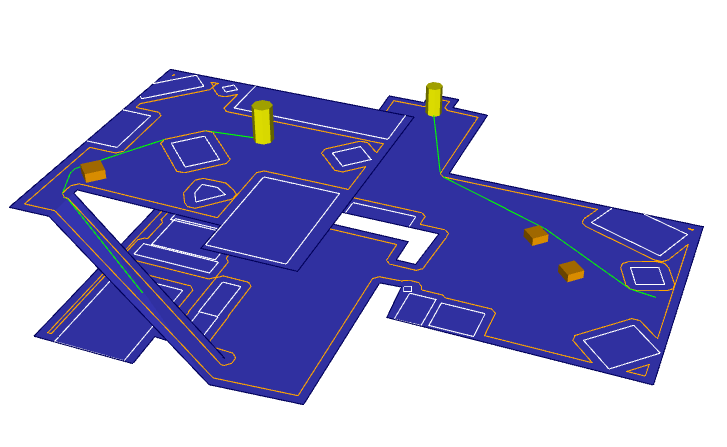
So first of all we have iMesh objects.
An iMesh contains the ground mesh data itself (drawn here in blue), as well as things like 'burnt-in obstacles' (white lines), and preprocess data to support pathfinding (including the boundary lines drawn in orange).
Burnt-in obstacles and preprocess will often be set up just once, at content generation or load time. By default these components are just bundled up as part of the iMesh object, and get destroyed at the same time as the iMesh, without any ownership or dependency issues.
But there's other, more dynamic stuff the user can do with their iMesh.
For example, 2D shapes can be placed at specific positions on the mesh, to act as obstacles (drawn here as orange solids), and/or pathfinding agents (drawn as yellow solids). In either case, the user places the shape and gets an iAgent pointer, which can be used to move agents and obstacles around, and to control which agents and obstacles are taken into account for a given pathfinding query.
Pathfinding queries return iPath objects (drawn here in green), and agents can be advanced along paths, with the path object updated to contain only the remainder of the path after the the advance.
Original approach: iMesh owns all upon it
It's kind of natural to consider the iMesh object as containing any iAgent and iPath objects placed on it, and this point of view strongly influenced the design of the initial API for managing these objects .
The idea was that when you create an iMesh object, you create a kind of independent pathfinding world (usually corresponding directly to a game level being loaded).
When a level is completed, and the game is ready to move on to the next level, it's kind of natural to want to go ahead and clean up everything associated with that completed game level.
So in the original PathEngine API design, when you deleted an iMesh object, PathEngine would helpfully go ahead and also clean up any iAgent and iPath objects left on the iMesh.
You could consider iMesh as 'owning' a bunch of these smaller sub-objects.
We can illustrate this setup as follows (with the arrows indicating that ownership relation):
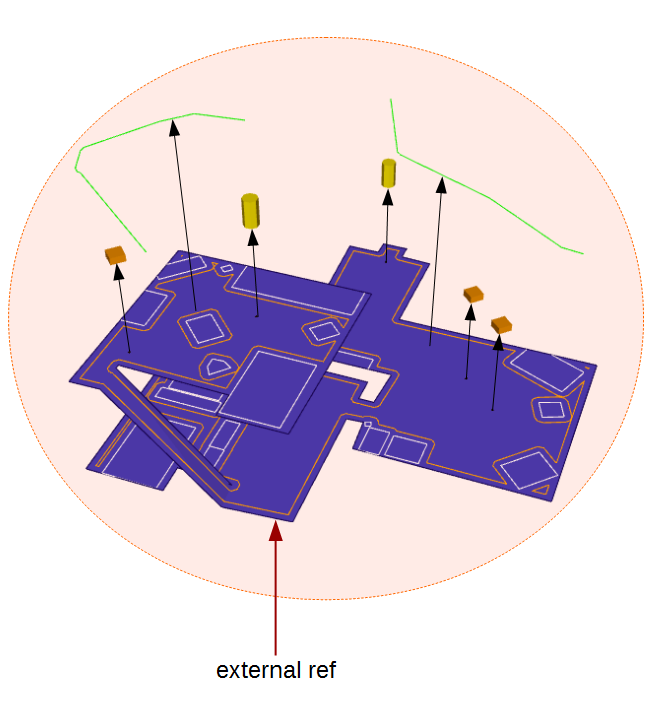
Delete owned subtree
PathEngine isn't just about meshes, agents and paths. There are other objects provided by the SDK.
The same kind of approach was then applied throughout the SDK, with the various API objects organised into a kind of tree structure.
In general, larger (containing) objects, towards the root of the tree, were given the responsibility of cleaning up a whole bunch of smaller 'owned' objects, in branches out from the root.
Let's call this approach delete owned subtree.
Advantages of this approach
The main advantages of delete owned subtree are both related to the fact that, with this setup, the client application is not responsible for keeping track of sub-objects, and cannot then forget to clean up any of those sub-objects.
So this helps avoid memory leaks, first of all.
And then having a paradigm that forces sub-object cleanup (for example when an iMesh object is deleted) is also a good way to avoid memory fragmentation.
Memory fragmentation nightmares
Memory fragmentation is an important issue for game development nowadays but was even more important historically, particularly for console platforms, when there was a lot less memory to go around.
Imagine your game is unable to allocate memory and crashes out, after loading a bunch of levels, during console acceptance tests, due to heap fragmentation. Your game can't be released until the acceptance tests pass, and each pass through acceptance testing involves a third party, bureaucracy, and delays.
This is one of those things that can be fundamentally hard to fix, a real developer nightmare.
Seemed like a good approach at the time
So what I'm trying to do here is to give a bit of context for the original PathEngine API design.
The point is not that this was some kind of perfect solution to memory leaks and fragmentation, but just that, given the kinds of priorities for game developers at that time, this was a reasonable enough way to approach object management.
And the approach worked out fairly well in practice, at least in that the SDK shipped with a whole bunch of games with these ownership semantics, and with very positive feedback from developers about the general API design.
But looking back at this design with slightly more modern programmer sunglasses, it's not too hard to see some problems with the approach.
Where this breaks down
Actually, the previous diagram doesn't really show the real situation with regards to object dependencies and references. Let's try and fill in some more of the details here.
The diagram might then start to look something like this:
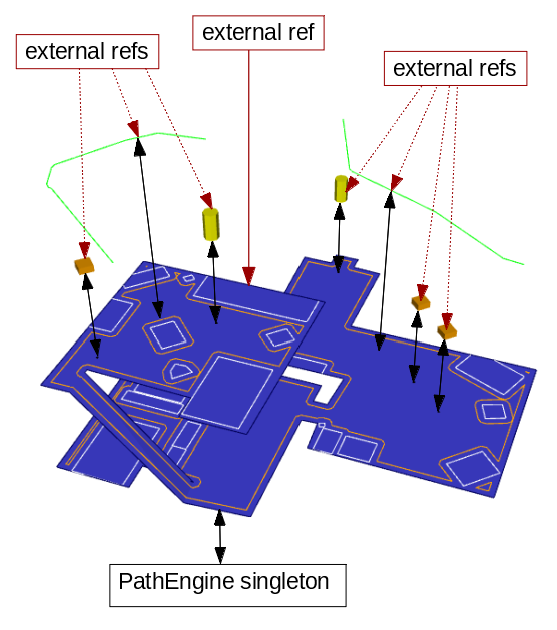
Weak references
The first thing to note is that the user will generally need to hold on to a bunch of those individual iAgent and iPath object pointers, in addition to the iMesh pointer, in order to actually do useful stuff with them.
In terms of actual concrete game code, maybe the iMesh pointer gets stored in with a bunch of other game level information, and the iPath and iAgent pointers get stored somewhere completely different, in with some AI classes, or somewhere like that.
So, as well the user's iMesh pointer (drawn in solid red, because the user is kind of considered to own the whole lot, through this reference) we also have a bunch of other 'weak references' (drawn with dotted lines).
And the problem is that there is nothing to prevent these weak references getting invalidated.
When the mesh is destroyed (e.g. on level completion), and all those path and agent objects also get destroyed, there's nothing to ensure that outstanding iPath and iAgent pointers held elsewhere in the code are cleared or otherwise marked as invalid, or to prevent other code from subsequently attempting to use these pointers.
Prioritising hard problems
I guess we could say that in days of console programming yore, there were some really hard problems that it made sense to prioritise over a bunch of smaller, detail issues.
So this included the problem of memory fragmentation, but similar logic could also apply to stuff like making the game run fast enough and fit into limited memory.
An access violation from dereferencing a bad pointer can be pretty clear in a debugger, and in comparison to those other potential nightmare problems not so hard to track down and fix.
And using tricky automatic memory management techniques didn't make sense if it slowed everything down to the point where your game couldn't be released.
So it was kind of ok to then 'just have to be careful' about things like ownership and pointer validity.
Times have changed
Times have changed, however, and we've moved forward as an industry.
Invalid pointer dereferences are bad news, and not always easy to fix, and with my modern programmer sunglasses on, delete owned subtree starts to look horribly unsafe.
If we're careful, we can implement safer constructs pretty efficiently, and with today's CPU and memory budgets the overhead for this is just not an issue.
Bi-directional references
So one big problem with delete owned subtree is the issue of pointer safety around weak references (perhaps enough in itself, I think, to look for an alternative approach), but there's another fundamental problem with the approach.
If you look back at the updated diagram you'll notice that the internal dependencies between objects actually go in both directions.
The thing is, iAgents and paths can't actually do that much by themselves. These objects need to reference the mesh they are on in order to interact with obstruction boundaries and overlapping geometry.
And in the other direction, iMesh has to hold references to owned paths and agents, to be able to clean these up.
This was true for interactions between API objects in general. (See, for example, the bi-directional dependency between iMesh and the PathEngine root interface, drawn in at the base of the diagram.)
And these bi-directional dependencies were the root cause of a lot of internal code complexity, and general heartache.
Complications, notifications, mutex locks and, oh my goodness!
So, as is usually the case with software, there are some additional complications.
For one thing, when finished with a path or agent, the user had to be able to delete that path or agent directly, in addition to being able to force cleanup of all paths and agents beneath a given mesh. So mechanisms are required for 'unlinking' smaller objects from larger contained objects, when deleted directly, as well as for cleaning up the smaller objects as part of larger object destruction.
And, as well as manipulating iAgent pointers directly, the user needed some way to set up sets of agents. This was handled through 'collision context' objects, with each collision context referencing a bunch of agents. With delete owned subtree, and the general idea that the user should be able to force object deletion, deleting an iAgent also had to remove the agent from any collision contexts that included that agent.
And did I mention that PathEngine supports multithreading?
All the code to manage these various bi-directional dependency relationships and different possibilities for object destruction now gets a lot more complicated.
This meant a bunch of carefully placed mutex locks, and a big old puzzle to solve about how to make this all work without any possibilities for deadlock.
In some cases interactions between objects were implemented in terms of objects 'notifying' other objects about changes or destruction, while in other cases, a 'reaping' strategy was used.
While this did all work (even with minimal blocking between threads for common use cases), the end result was quite tricky to get your head around, and not something you really wanted to mess with.
User responsibility for multithreaded object deletion
PathEngine generally ensured thread safety for arbitrary synchronous calls into API methods, and most of the time all you had to worry about was whether or not multithreaded method calls could block.
But one situation where you were not protected, as a user, was when deleting API objects.
Attempting to call into an API object after it has been deleted is not allowed, clearly.
And then attempting to call into an API object while simultaneously deleting the object (or making some call that would eventually result in the object being deleted) is a race condition. This could also potentially result in calling into the object after deletion, and is therefore not permitted either.
That's actually kind of cool, from the point of view of a coder tasked with adding multithreading to an existing API, because it allows you to effectively ignore a whole bunch of potential interactions as being 'user error'.
(Maybe you're looking at a method on iAgent, and trying to work out the exact synchronisation requirements, and you start thinking about stuff like 'what if the mesh is in the process of being destroyed?'. Well no, you don't have to worry about synchronisation at all in this case. This is user error!)
That's a bit of a cheat, though, when you think about it. There's a real problem to be solved here (synchronising stuff around object destruction), and all we've done is shift the problem up to the user of our API.
Basis for a solution: reference counting
So broadly speaking, there are two general approaches to these kinds of pointer validity issues in programming: garbage collection, and reference counting.
Garbage collection isn't very popular in game development because of concerns about the unpredictability of collection delays, and the desire for precise control of when exactly resources get cleaned up.
And we already had some code for intrusive reference counting that we were using internally, so it was natural to extend this to external API object references, also.
Handle target base class
Here's the base class we use for referenced counted objects:
class bHandleTarget { mutable cThreadSafeRefCount _count; virtual void* mostDerivedPtr() = 0; bHandleTarget(bHandleTarget const&) = delete; bHandleTarget& operator=(bHandleTarget const&) = delete; protected: bHandleTarget() {} virtual ~bHandleTarget() {} public: void incRef() const { _count.incRef(); } void decRef() const { if(_count.decRef()) { bHandleTarget* nonConstPtr = const_cast<bHandleTarget*>(this); void* mostDerived = nonConstPtr->mostDerivedPtr(); nonConstPtr->~bHandleTarget(); GlobalAllocator().deallocate(mostDerived); } } bool hasMoreThanOneRef() const { return _count.hasMoreThanOneRef(); } };
The mostDerivedPtr() stuff is a bit of a hack to make our setup for customised memory allocation work correctly with virtual base classes. So just ignore this part, I guess, and imagine this being replaced by a call to 'delete this'.
And btw. I'm not proposing this code as something anyone else should use. The point of showing this code is just to make things a bit more concrete.
(This is code that works well for us, but if you want to set up something like this, from scratch, you should probably look at some other resources, e.g. maybe here, or here.)
Anyway, lets look at how this is used.
As part of object construction, first of all, it's the responsibility of calling code to make one initial call to incRef(), to enable reference counting for the object, and reflect the starting reference.
And then, after that, other code can basically just call incRef() when taking a reference to the object, and decRef() when it is no longer needed, without worrying about what is going on in other threads.
The object will automatically get cleaned up, directly and immediately, at the point of last decRef.
The incRef() and decRef() methods are enough for normal usage. We'll see what hasMoreThanOneRef() is for, later on.
Thread safe reference count
So the multithreading support is kind of magic, in that you can use this across multiple threads, and it just works.
To see how, we need to look inside that cThreadSafeRefCount data member.
On a single threaded build, this could be defined as follows:
class cThreadSafeRefCount { int _i; public: cThreadSafeRefCount() : _i(0) { } void incRef() { ++_i; } bool decRef() { --_i; return _i == 0; } bool hasMoreThanOneRef() { return _i > 1; } };
But on a multithreaded build however, on Windows, it looks like this:
#include <windows.h> class cThreadSafeRefCount { LONG _i; public: cThreadSafeRefCount() : _i(0) { } void incRef() { InterlockedIncrement(&_i); } bool decRef() { return InterlockedDecrement(&_i) == 0; } bool hasMoreThanOneRef() { return InterlockedExchangeAdd(&_i, 0) > 1; } };
These calls into the Windows interlocked API methods do the same thing as the single threaded version above, but with the guarantee that the operations are implemented atomically in the case of simultaneous accesses to the data member from multiple threads.
These kind of atomic operations should be faster than mutex locking, but, more importantly, there's no mutex locking here, and we know that this code will never block, or deadlock.
Reference counts instead of weak references
Reference counting gives us a way to fix the 'weak references' problem.
We can derive our API objects from bHandleTarget and add our own references to the object, internally, but also increment the reference count whenever we give an API object pointer out to the user, and provide some mechanism for the user to tell us when a pointer is no longer used (at which point we decrement the reference count).
The idea is that anything that holds a pointer to an API object also adds to the reference count, such that it is no longer possible for the object to be deleted while that pointer is held.
Let's call this approach reference counted API objects.
No cycles allowed
But there's a problem with this kind of simple reference counting strategy which prevents it being applied as described to arbitrary sets of interrelated objects. (Otherwise no-one would need garbage collection, right?)
The problem is that simple reference counting approaches don't support cyclical references.
And specifically, if you set up situations with cyclical references, and rely on reference counting for object deletion, your objects will never get deleted.
In our concrete situation with iMesh, iAgent and iPath, if iMesh holds a reference to an iAgent object, and the iAgent also holds a reference to the iMesh, we have a problem.
Turn it all upside down
The key insight here is that the objects that we previously considered as 'container' objects don't actually depend, fundamentally, on their sub objects.
In our example, iMesh doesn't actually need any references to iAgent or iPath (other than to keep track of a list of objects to clean up).
And it turns out that with a little bit of manipulation, the same thing is generally true for the rest of the SDK.
So we can keep the same kind basic tree structure of dependency relationships between the objects in the SDK, but turn the whole thing upside down.
Let's make a new diagram then, but but with the arrows pointing in the other direction.
Where the arrows previously meant something along the lines of 'contains and owns', these arrows now have a very clear and well defined meaning, specifically 'holds a reference to'.
The arrows all go in one direction, and our dependency tree is now a directed acyclic graph:
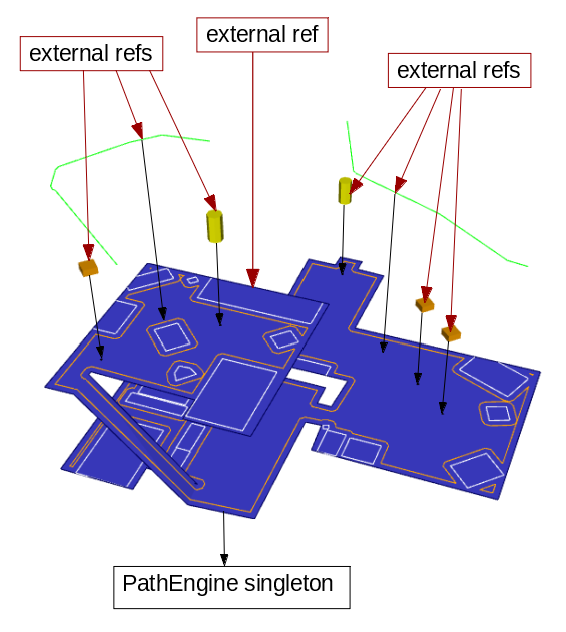
With a directed acyclic graph of dependencies, object dependencies can no longer form cycles, and a simple reference counting approach can now be used.
The arrows now all represent strong references. As long as one of these references is held, the referenced object will not be deleted.
That works recursively, so as long as you hold a pointer to an agent (for example) the mesh itself will not be destroyed. iMesh references the PathEngine root interface object (actually no longer implemented as a singleton) in the same way and generally, instead of big objects owning lots of smaller ('contained') objects, we now have a bunch of smaller objects sharing ownership of larger, more fundamental, objects.
But what about deterministic destruction?
But hold on one moment! (You might say.)
There were good reasons for the SDK to provide forced destruction semantics. (All that stuff about memory leaks and fragmentation!)
With our new 'tree of references', it's no longer possible to force destruction of all those mesh sub objects when a level is completed.
And, worse than that, while any of the small sub-objects remain alive, and hold references to objects lower down the tree, there's no way for the user to force deletion of those larger objects.
If one agent pointer reference is held, there's now no way for the user to force destruction of the containing iMesh, and reclaim the memory that it's occupying.
hasMoreThanOneRef() to the rescue
The trick here is to give up a little bit of control.
Being able to force deletion of an object that may be referenced by other code conflicts fundamentally with guarantees that the other code can safely use that reference.
So I suggest we stop trying to force things to happen.
But what we can do (very easily, as it turns out) is check for outstanding references to an object we would like to delete.
The solution is then to replace code that looks like this:
// (this would delete the mesh, // and all remaining sub-objects) mesh->destroy();
With something like this:
assert(!mesh->hasMoreThanOneRef()); // (if the assert succeeded, // then we know the next line will // actually destroy the mesh) mesh->decRef();
This assertion says 'I insist on destroying this mesh right now, and so nothing should be holding on to any references to the mesh, or sub-objects of the mesh, when we get to this point'.
This way, while it's still up to the game code to make sure no references are leaked by detail code, this is something that is checked for, and will be caught if it happens.
API object reference leaks
What if there's a bug in some detail user code (for the AI update of some entity, for example) that results in an agent pointer being 'leaked' (discarded without us being told to release the corresponding reference)?
So this can be detected very easily, but that doesn't tell the user exactly where to find the leak, and tracking down the exact leak location can be kind of a pain.
It's very similar to the issue of memory leaks, in general, and, just as with memory leaks, it's a good idea to use automatic lifetime management, to avoid the possibility of these kinds of leaks happening, in the first place.
API interface
The PathEngine API is designed to work across a DLL boundary.
For this, the interface objects (such as iMesh, iAgent, iPath) are provided to user code in the form of a set of virtual base classes, and we depend on compilers either side of the DLL boundary respecting the COM specification.
(Some old but good information about this kind of setup can be found here.)
The important point, as far as this post is concerned, is that user code cannot be allowed to call the destructors for our interface objects directly, since different memory heaps are used each side of the DLL boundary.
So we already use a 'trick' with custom operator delete to redirect delete on API object pointers into PathEngine internal code (running on 'inside' the dll boundary), and the user ends up seeing something like this:
class iPath { public: virtual bool hasRefs() const = 0; // release() calls on to decRef(), internally virtual void release() = 0; //... other interface methods void operator delete(void* voidPointer) { if(voidPointer) { iPath* afterCast = static_cast<iPath*>(voidPointer); afterCast->release(); } } };
User code that calls this might then look something like this:
// this creates a path, // and adds one to the ref count, // for our 'external ref' iPath* path = agent->findShortestPathTo(context, target); //... do stuff with the path // this releases our 'external ref' // and if no other references were taken // the path will be deleted delete path;
std::unique_ptr and std::shared_ptr
Because of the simple call to delete when the user has finished with an API object pointer, standard STL scoped pointer types can be used directly with these object pointers, without the need to set up a custom deleter.
So the 'manual' reference count management above can be replaced with the following:
{ std::unique_ptr<iPath> path(agent->findShortestPathTo(context, target)); //... do stuff with the path // our 'external ref' gets released automatically // at end of scope // and if no other references were taken // the path will be deleted }
The same goes for shared_ptr, if required, and you can put these in containers (such as std::vector), and generally benefit from all the good automated lifetime management stuff provided by these scoped pointer types.
Diligence is required, but diligence is good!
In practice, this still leaves users upgrading from previous versions of PathEngine with a certain amount of pain.
Code that was previously correct, based on the assumption that deleting an iMesh would clean up any outstanding sub-objects, now needs to be updated to ensure that all of these sub-objects are explicitly released.
And, although automatic lifetime management helps a lot with this, any code anywhere leaking any API reference prevents all larger objects from being destroyed.
Actually, the possibility to leak API objects is not new.
Client code could repeatedly create, and then fail to destroy, agents or paths, before the change to reference counted API objects. The difference is just that this problem could previously be covered up by the fact that these objects would all get cleaned up eventually, anyway, on mesh destruction.
The difference is not in the possibility for objects to be leaked, it's that it's no longer possible to ignore small leaks, and 'get away with it'. You're kind of obliged to do things correctly throughout your code. And, while requiring a bit of diligence, reference counted API objects actually gives the user more control over object lifetimes, in that this makes it possible to check that objects really are being destroyed as and when they should be.
Big picture
Here's a full graph of dependency relationships in PathEngine, at the time of writing (taken from here):
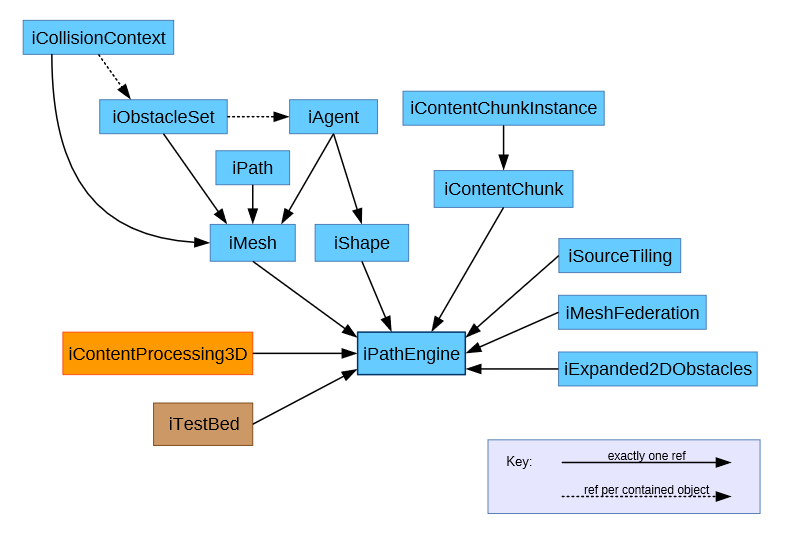
Internal code simplifications
Apart from the external pointer validity issues, switching from delete owned subtree to reference counted API objects also resulted in very significant reductions of internal code complexity.
As a result of this change we were able to replace a bunch of tricky mechanisms for registering and unlinking objects, together with synchronisation between this code and other code for preprocess generation and run-time queries, with just one handle data member per API object reference.
To give you an idea about how this change actually feels, from the point of view of someone working on the code, before the change I remember feeling strongly averse to the idea of making changes to certain parts of the code. Anything related to lifetime management for collision contexts and agents, in particular, was a nightmare, as well as other code having to synchronise with this. Looking at that ownership graph now, however, the whole ownership side of things seems completely trivial. (I almost want to add some more API objects into this graph, just for the hell of it.)
Conclusion
Switching to a reference counted setup, in the specific case of the PathEngine API:
- solved a bunch of pointer validity issue
- (with it no longer possible for unrelated code to 'pull the rug out from under' other code holding references to PathEngine objects)
- solved tricky issues with multithreaded object deletion (without making the user responsible for this)
- enabled us to significantly simplify parts of the SDK internal code
- made stuff more efficient, and avoids blocking
- while enabling us to maintain essentially the same set of API objects and tree structure, and minimise disruption for existing clients
Reference counting isn't compatible with forced deletion, but you can assert that objects will be deleted instead, and this can actually work out better in the end (with more control over object lifetimes).
More generally, reference counting is a great way to manage object lifetimes, but with the significant caveat that objects must not form cycles. That can be a problem for general ownership management, but as API designers we have the power to organise dependencies between API objects, and in many situations we can choose a directed acyclic graph.
Getting the arrows the right way around helps a lot with this. (Larger, originating objects often don't actually depend on the objects they are used to create.)
Direct acyclic graphs are also great things to work with, generally, with one-way dependencies making for simpler code.
And then, with a directed acyclic graph of dependencies, the user cannot create cycles of API objects. The caveat about reference counting and cycles quietly disappears, and reference counting becomes something of a perfect way to manage object lifetimes.
If you're designing an API, if your API objects have dependency relationships, and if the user needs to manage object lifetimes, maybe reference counting is the ideal approach for this.