Vector Hosted Lists
Vectors are great when adding or removing elements at the end of a sequence, but not so hot when deleting elements at arbitrary positions.
If that's a requirement, you might find yourself reaching for a pointer-based list.
Not so fast!
Memory locality is important, contiguous buffers are a really good thing, and a standard vector will often out-perform pointer-based lists even where you perform non-contiguous, list-style modifications such as arbitrary element deletion.
And we can 'host' a list within a vector to get the advantages of a contiguous buffer at the same time as 0(1) complexity for these kinds of manipulations.
Motivation
I actually have two goals in writing this post:
- to talk about the general idea of 'hosting' a list within a vector
- to introduce a specific data structure that will be reused in my next post
Hosting a list in a vector ain't rocket science, but I think it's a good technique to have in mind when designing data structures generally, and it's definitely a worthwhile topic to include in a series about vector based data containers.
We'll be looking at one specific example, based on this technique, for which I have a fairly specific set of requirements.
The requirements come from a larger use case for mesh representation in PathEngine. We'll look at the overall context for these requirements in more detail in my next post and together I hope that these two posts serve as a compelling example for how vector hosted lists can be used to make a good solution to some concrete real world problems!
Requirements
What I need is essentially a container for a bunch of elements, but I'll need to:
- iterate through the elements
- hold on to references to individual elements
- add new elements
- delete individual elements
without changes to the set of elements (and in particular element deletion) affecting existing references to the remaining elements.
(We'll look at the requirements for the actual element type in more detail later on.)
A straight forward linked list data structure would be fine for this.
With a linked list we can use pointers to list nodes as both iterators and element references, with these pointers remaining valid as references across the removal and deletion of other list nodes.
Never use linked lists?
In his keynote for GoingNative 2012, Bjarne Stroustrup talks about some benchmarks comparing std::vector and std::list. The (perhaps surprising) result is that std::vector works out to be faster in practice than std::list in some situations where lists would traditionally have been the natural choice.
This point is discussed in more detail in this blog post. ('Why you should never ever ever use linked list in your code again', the article is also reposted on code project with some additional discussion in the comments there.)
I recommend reading that blog post for a more detailed discussion of this issue, concrete benchmarks, and so on, but in a nutshell it seems that as the difference in latency between CPU cache and main memory becomes more significant, contiguous buffers become increasingly desirable, and we see vectors out-performing pointer-based lists in many cases where arbitrary non-contiguous element manipulation is required.
So the reduced algorithmic complexity for linked list manipulations can be outweighed by the much lower constant factors resulting from better caching for contiguous buffers.
Use std::vector?
So should we just switch to std::vector?
Well, of course, all depends on context, and Kjell admits that the title of his post is hyperbole.
My experience is that we ignore algorithmic complexity issues at our peril, and I'd much rather get the algorithmic complexity of linked list manipulations, whilst keeping the advances of contiguous buffers, if this possible.
More fundamentally, apart from being (algorithmically) inefficient, std::vector erase() doesn't actually meet our requirements.
Erasing an element from the middle of a vector results in all the other elements after that being moved down, to close the 'hole'. And that means that (whether we use element indices or pointers as element references), references to elements after an erased element will be invalidated (or at least need to be adjusted) after each element deletion.
So a straight switch to std:vector doesn't work here. We need some of the detail semantics of linked lists with regards to iterator validity, in addition to performance characteristics.
Direct translation
It turns out that we can actually take any list data structure (i.e. a data structure based on fixed sized nodes and pointers to these nodes), and convert it to a vector hosted version.
The vector buffer takes the place of the memory heap, and selecting an unused entry in the buffer takes the place of arbitrary memory allocation.
And we can then also use element indices in place of generalised pointers for node references, so that these node references remain valid across vector capacity changes.
So another option could be to take some standard linked list code, and translate this to a vector hosted version. Let's look at this in some more detail.
Vector hosted double linked lists
If we have a double linked list structure that looks something like this:
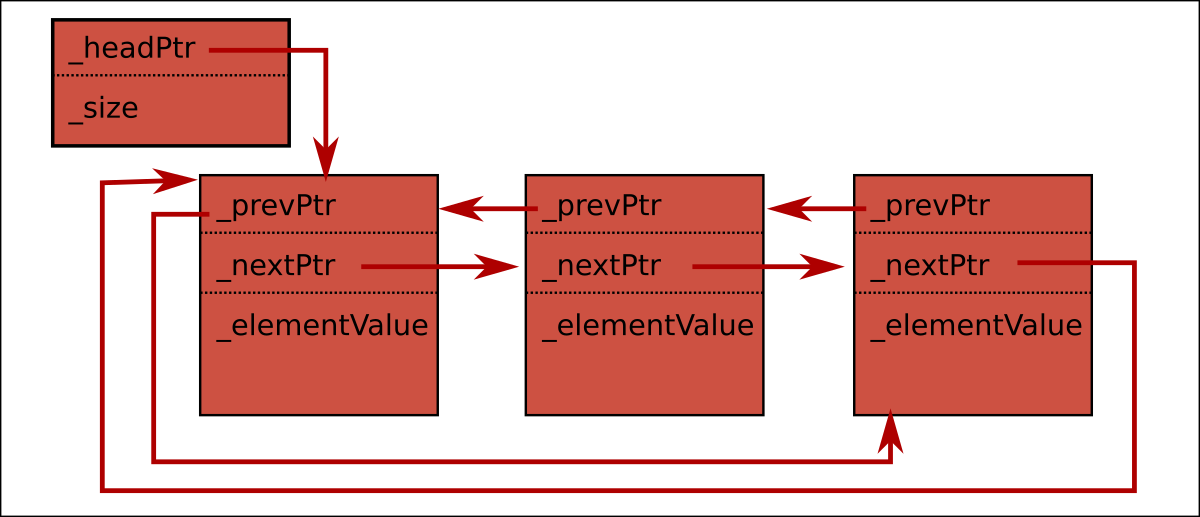
We can 'host' this in a single contiguous vector buffer as follows:
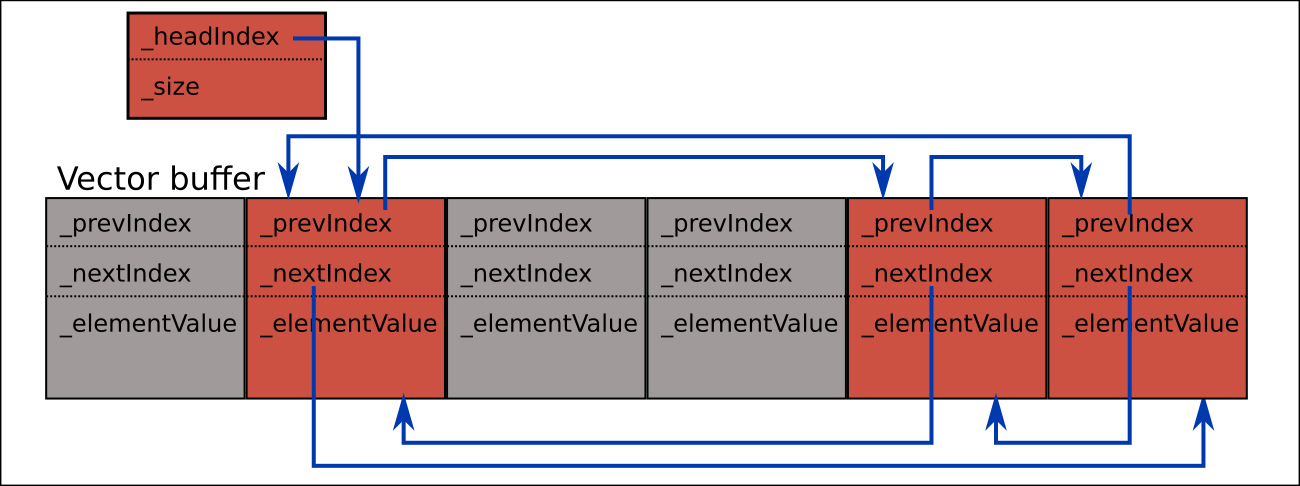
We can start by allocating buffer entries in order, but after entries are deleted there are going to be some holes (shown here in grey) and then we need to do our own 'memory allocation'.
It's much simpler than general case arbitrary memory allocation, though, and all we actually need to do for this is to chain the unused entries together in free list.
A singly linked list is sufficient for this purpose, and we can reuse _nextIndex:
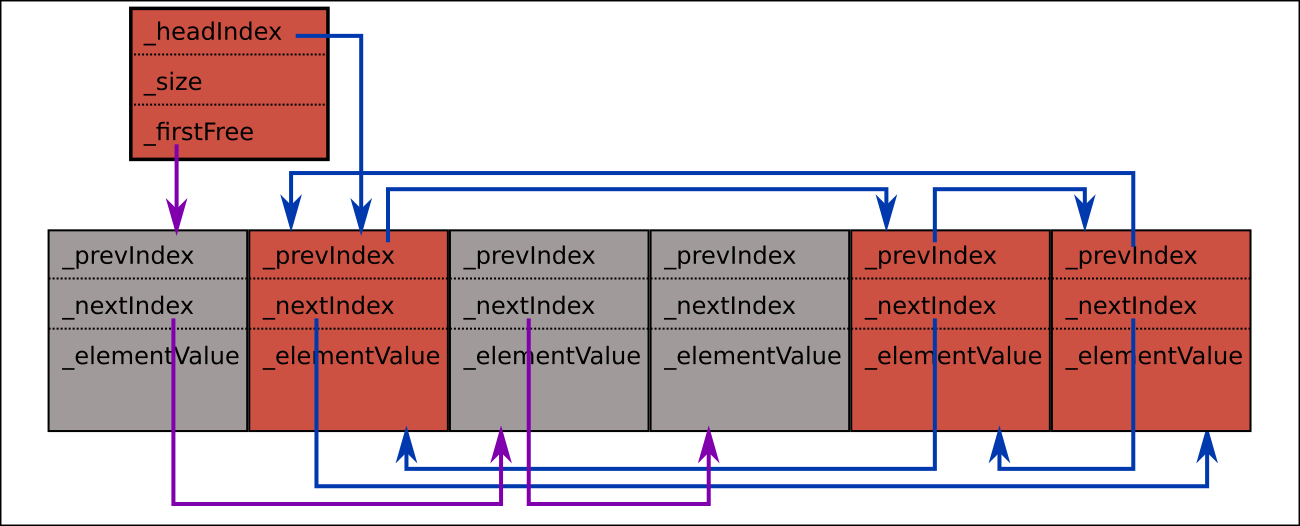
To 'allocate' a new node we take the element at _firstFree and update _firstFree to the next in the free list (or, if there are no free elements, push a new element on the end of the vector).
If we have a bunch of linked list manipulation code that was designed for the original layout (a traditional pointer based list), it's straightforward to adapt this to the new 'hosted' layout. We basically just:
- change iterator type (and associated increment, decrement and dereference operations)
- switch to the free list based 'memory allocation' strategy.
So I guess a first point to make here is that 'hosting' a list data structure in this way is really not so hard to set up.
But what does this give us?
If you squint a bit, you may notice that the end result is actually very similar to what you get if you stick with a pointer based list, but add in a custom allocator that allocates list nodes from a single (contiguous) memory pool. So to some extent, you could argue that you might as well just go ahead and do that instead. But one advantage in the case of 'vector hosting' is that the underlying buffer can actually now be resized dynamically in a vector kind of a way (so extended with amortised cost, and 'shrunk to fit', as desired). And there are other reasons to prefer element indexing to generalised pointers, for example with element indices being easier to load and save.
Just as with the memory pool, we'll see some reduction in memory allocation overhead due to the simpler memory allocation strategy.
And, just as with the memory pool, our list nodes are now all in one contiguous memory space, so we can expect better locality of references, and hopefully some increased performance due to this.
But, unlike std::vector, the hosted list doesn't keep our elements ordered in memory, and iterating through the elements in sequence order can potentially mean jumping around arbitrary positions in the host buffer, which isn't so good.
And those _prevIndex and _nextIndex values are a bit chunky.
In our specific use case at PathEngine, _elementValue is actually going to be just a single integer value, and adding _prevIndex and _nextIndex multiply memory footprint by 3!
Our specific use case is in the implementation of a mesh data structure. In most cases we expect to only edit part of the mesh at a time, we're ok with periodically 'consolidating' mesh data, and we'd like our sequence representation to be as close to a raw vector as possible!
So we're going to implement this a bit differently, but we've seen how straightforward it is to 'host' lists in a vector, and we'll still leverage this idea to some extent.
Holes and dead entries
What we'll do is to implement something pretty close to a raw vector, but with a concept of 'dead entries'.
We basically replace the standard 'copy everything down to make contiguous' deletion semantics from std::vector with a mechanism that just flags elements as dead, on deletion, but leaves these 'dead' elements in place, and reuses them as and when new elements are required.
It turns out that we can do this, in our specific use case, without needing any extra data for flags or _nextIndex, but we'll need to look at the specific requirements for _elementValue in a bit more detail.
In our mesh use case, element value can either be a positive integer (0 included), or a special value of -1. (-1 is used an a kind of 'invalid value' indicator). This leaves values below -1 available for marking dead entries.
So we define any element with _elementValue set -1 as flagging as a dead entry. But the actual negative value used here can also encode a _nextIndex value for our free list.
The _nextIndex values needing to be encoded include positive integers (0 included), specifying the next free entry, and (another) special case value of -1, which in this case means 'no more free list entries' (so the equivalent of a null pointer).
To encode _nextIndex (an integer greater than or equal to -1) as a dead element marker (an integer less than -1) we use the mapping f(x) = -3 - x. If you check, you'll see that the same function also works for conversion the other way (to obtain _nextIndex back from a dead element marker).
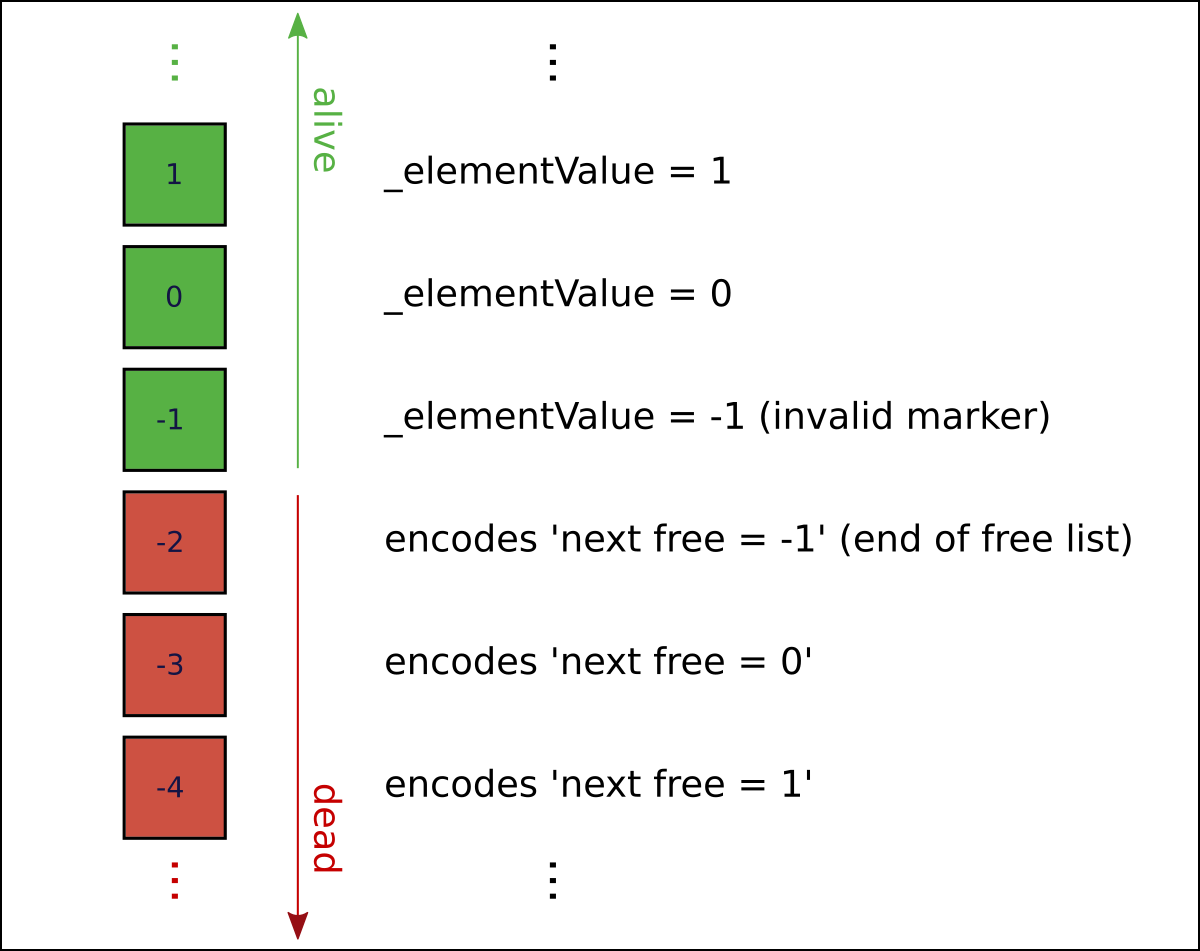
In PathEngine this encoding is actually wrapped up in a 'named integer' class, which helps avoid programmer errors. This adds a lot of lines of code, however, so I'll be stripping the named integer stuff out of the example code, and we'll work with raw integer values directly.
Anyway, we end up with a sequence representation that looks something like this:
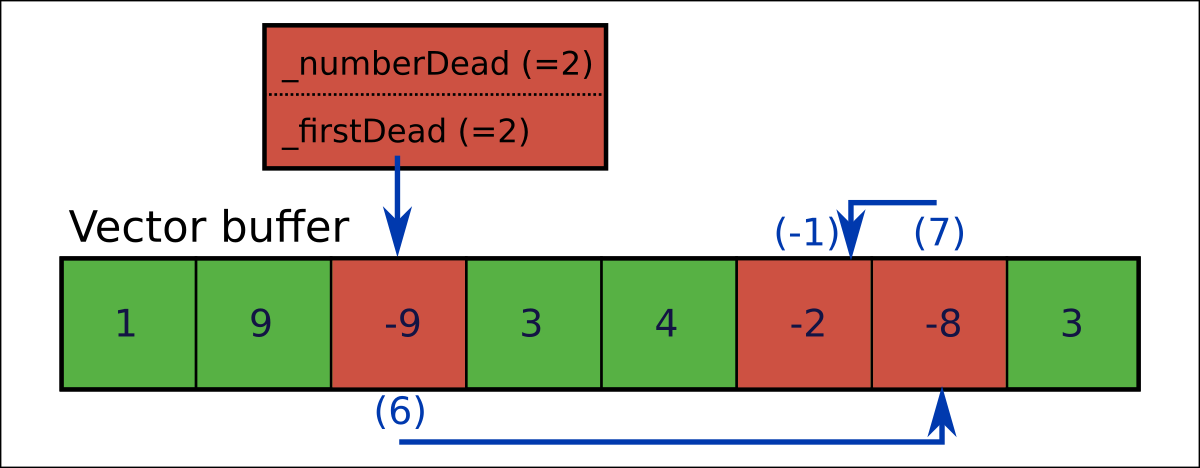
This stores the sequence [1,9,3,4,3], but note that, in order to iterate through this sequence, we'll need to check for and skip dead entries as we go.
By keeping track of the number of dead entries we can work out the actual number of contained elements based on the size of the underlying vector.
Implementation
A stripped down implementation for this is as follows:
#include <cassert> #include <vector> #include <cstdint> class cVectorWithDeadEntries { std::vector<int32_t> _v; int32_t _firstDead; int32_t _numberDead; public: cVectorWithDeadEntries() { _firstDead = -1; _numberDead = 0; } bool empty() const { return _v.empty(); } int32_t size() const { return static_cast<int32_t>(_v.size()); } int32_t addEntry() { int32_t index; if(_firstDead == -1) { index = size(); _v.push_back(-1); } else { --_numberDead; index = _firstDead; _firstDead = -3 - _v[index]; _v[index] = -1; } return index; } void markAsDead(int32_t i) { _v[i] = -3 - _firstDead; _firstDead = i; ++_numberDead; } bool entryIsDead(int32_t i) const { return _v[i] < -1; } int32_t numberDead() const { return _numberDead; } int32_t operator[](int32_t i) const { assert(!entryIsDead(i)); return _v[i]; } void setValue(int32_t i, int32_t value) { assert(!entryIsDead(i)); assert(value >= -1); _v[i] = value; } };
We reuse std::vector here to avoid reimplementing the wheel. (Although, in PathEngine, we actually reuse a custom vector implementation!) In real code, however, this means you'll probably find yourself wanting to add some more pass through methods to access the functionality of that underlying vector (such as different constructor versions, and things like swap(), or an explicit push_back() operation).
Note the explicit setValue() method. We could also, alternatively, return some kind of proxy object from operator[], to allow element values to be set directly through that indexing operator.
Consolidate
If a lot of elements get deleted, we can end up with a lot of dead elements, and then it's nice to be able to free up some of this memory and get back to a contiguous sequence of elements:
void consolidate(std::vector<int32_t>& remaps) { remaps.clear(); remaps.resize(size(), -1); _firstDead = -1; _numberDead = 0; int32_t remapped = 0; for(int32_t i = 0; i != size(); ++i) { if(!entryIsDead(i)) { remaps[i] = remapped; _v[remapped] = _v[i]; ++remapped; } } _v.resize(remapped); }
If you hold on to element references across this call then these element references can be invalidated, but a table of remaps is returned to enable you to update these references.
Conclusion
We'll see a bit more about exactly how cVectorWithDeadEntries is actually used, in PathEngine, in the next post, but it should already be clear that there can be good alternatives to old fashioned linked lists, if you're willing to knock up a bit of custom container code.
Hosting lists in a contiguous buffer can give you some significant advantages, in both cache efficiency and reduction of memory allocation overhead.
Direct element indexing can also be an important additional advantage. cVectorWithDeadEntries effectively gives you random access read and write permissions to the contained sequence, and this may allow you to do some stuff you wouldn't be able to do with a linked list. And element indices are a lot more convenient when making data structures persistent, and can be easily packed into a smaller number of bytes if necessary.
If you're working with linked lists (or some other linked data structure with fixed size nodes), and you need the best possible performance, consider:
- switching to a std:vector
- hosting your data structure in a vector
- building a custom vector hosted container!
Benchmark, and test what is actually fastest in your specific application context!
Comments (discussion closed)
Congratulations, you've implemented a lisp heap. Go on like that, eventually you'll have implemented a whole lisp.
Thanks!
btw. Do you have any references for that?
(Equivalent
or similar lisp heap data structures, not implementing a whole lisp, I
think I'll be taking a different direction from here. ;) )
A lisp heap, just like any heap in any other programming language (eg. C malloc), is just a vector of byte (or vector of words). Using indexed addressing or absolute addressing doesn't change the access patterns. Implementing such a heap in a vector of the language will, eventually, lead to the same advantages and the same inconvenient.
Now, of course, the advantages of cache locality are lost when you have a very big vector, like, the whole memory. That's why modern lisp implementations use generational garbage collectors (and with younger generations per thread even!), so that memory is allocated locally, as if in a single little vector.
Implementing manually efficient memory management is hard. Adaptive algorithms such as generation garbage collectors are bound to be more efficient in general.
For the rest, refer to Greenspun's Tenth Law.
In the article we actually set up a vector of *list nodes*, so you can think of this as like a *very specialised heap* which only has to ever deal with blocks of one single known size. This is much easier than generalised memory management.
Using indexed instead of absolute addressing does make the difference that we can resize our vector without references being invalidated. If we use absolute addressing then we can't resize our vector, so we're not actually using 'vector' functionality (and could just talk about a 'block of memory', or 'memory buffer' instead).
Your definition of heap may need refreshing. Or alternatively you may also need to read the article.
Nice write up. I would love to see some simple benchmarks with this container compared with std::vector and std::list (possibly also skip list http://en.m.wikipedia.org/w... to see the strengths and the weaknesses.
It's just a suggestion ;)
If it's more efficient than (X) then a lot more people are going to want to try it out
Hi Kjell,
I prefer benchmarking, ideally, when I actually have a decision I need to make, myself, and a concrete benchmarking context.
(So there's the kind of selfish and lazy aspect, then, that I don't do 'wasted' work, but this also helps keeps benchmarking grounded and honest, I think, as I'm less likely to end up setting up micro benchmarks that don't reflect actual real world situations, or straw man benchmarks!)
In this case cVectorWithDeadEntries is something that was applied some time ago, in PathEngine.
The context for this change will become clearer in my next post, but we did benchmarking around the change and there were some pretty nice improvements in both memory footprint and content processing speeds.
In a way, though, the performance improvements are just a nice bonus, and unless cVectorWithDeadEntries actually ends up *significantly slower* than a linked list, it's already preferable for us, in our concrete use case situation, due to the much better memory efficiency and direct element access by index.
For the memory efficiency side of things, if you compare with a standard linked list without custom allocator then don't forget there's also a load of overhead to be taken into account in the system memory allocator, (which may be harder to measure properly), in stuff like memory allocator data structures and padding!
Thomas
list_pool by Alexander Stepanov:
http://www.youtube.com/watc...
Cheers Evgeny. I love his teaching style!
Hi Tomas. He actually starts to talk about list_pool in previous video - Lecture 8 Part 1, 11:45.
Anyway, when you have time - I recommend you to watch all his lectures, his talks are very instructive and inspiring.
What about "hold on to references to individual elements" requirement? When hosting vector resizes, it will rellocate the storage leaving all external references dangling.
No. This is why we changed from pointer to index based element referencing.
Pointers are not references. Indices are not references. The point Szymon was making is that when a std::vector grows, the memory backing it will change locations. In this limited case where elements are accessed by value it's not a problem, but if you want to store larger types and access them through something like T& operator[](...) it could become problematic. using std::deque to host the list would eliminate that, but that comes with it's own performance overhead.
Ok, yeah, when I say 'element referencing' here I'm not talking about C++ references.
But yes, there can be issues with T& operator[](...), since what you get back from this is actually a pointer to the element, at the machine level.
So this comes up, for example, if you do something like:
This is an issue with vectors, in general, not just with vector hosted lists.
You could get around it, I guess, by making operator[] return some proxy with a pointer to the vector plus index (but that can introduce other issues).
And yes, 'deque hosted lists' could be another thing to consider..
I implemented something very similar in C# with an array of structs (pre-allocated to max capacity) plus an auxiliary array of indices to keep track of the used and free list. With a little bit of extra work at element insertion and removal time it is possible to keep the used and free lists in contiguous memory order, to maximize cache performance when iterating. (I iterate by walking the used list rather than iterating the whole array and skipping "dead" items.)
Hi Yossarian
I don't really understand what you're doing with the used and free lists, to be honest.
(I don't think you mean that the indices vector is actually partitioned into two parts, otherwise you wouldn't need this index vector at all. So it seems like the used and free lists must skip over each other. Do you just mean that the next pointers of these lists always go forwards?)
But keeping a separate vector for the indices can be a good variation, I think. (This is like separating elements in vectors across multiple vectors, in general. You can do this to choose exactly what most benefits from shared cache lines, or also to reduce dependencies.)
And, because you're using indices, it sounds like you probably could switch from 'pre-allocated to max capacity' to 'vector hosted', if you needed to do this..
I have an array of structs of length N. I have a second array of integer indices, also of length N, used to keep track of which elements in the first array are in use and which are available. Each entry in the index list is the index of the next element in the list. I also keep track (in separate variables) of the index of the first used entry and the index of the first free entry. So to walk the elements that are in use looks something like this:
for (int i = first_used; i < struct_array.Count; i = index_array[i])
{
DoSomething(ref struct_array[i]);
}
Note that the final reserved entry in the index array will index off the end of the struct array, hence the test against Count. (I suppose a -1 marker might be slightly more efficient.)
When I add an element to the collection -- i.e. reserve a free slot from the struct array -- I use the first element in the free list, but I link it into the used list so as to preserve memory order of accesses. That is, the above loop always advances through memory, it never steps backwards. Similarly, when I remove an element -- i.e. return a slot to the free list -- I put the free slot back into the free list in memory order. In my implementation I use 16-bit short integers for the index array, and free entries are stored as negative numbers. This lets me easily scan backwards or forwards from a specific index to find a free or used slot. 16-bit short indices with a sign bit means I can store a maximum of 32,767 entries in my struct collection, but that was fine for what I needed. Adding an element is O(1). Removing an element is technically O(N) due to the need to search the neighbourhood of the released item to find adjacent free and busy entries, for list management -- but in practice it usually only searches a few elements, so is very cheap.
Ok Yossarian, got you. (I think!)
So you end up iterating always forward through memory, but with stuff to skip, which is similar to the situation for 'vector with dead entries' after some entries have been deleted.
Do you have some kind of equivalent to the 'consolidate' operation, to get rid of those holes?
Did you do any benchmarking with this data structure?
That's right, I iterate but skip dead entries. When I allocate new entries, the dead holes at the front get reallocated first, which will also have good cache behaviour. I don't have an explicit consolidation mechanism, though I guess it could be added -- the trouble is client code may have cached an index which will no longer be valid.
I don't have benchmarks that you will find useful. I built this system while refactoring an entity-component system, and the only benchmarking I did was to confirm that the new solution was no slower than my previous approach. (The old approach was hard-wired into the entity system, while with my new system I get a general purpose struct pool implementation that can be used independent of the entity system.)