Fast Resettable Flag Vector
Another custom container post for my Vectors and Vector Based Containers series.
In this post I'll look at an alternative implementation of the humble bit vector, designed specifically for optimising zero fill operations.
It's not a new technique, and not particularly complicated to implement, but it's not completely obvious, and it's something that gave us some noticeable speedups when applied to PathEngine so I think it's worth sharing here.
Motivating example
Some algorithms need to flag elements in a data structure being processed, to avoid repeated processing, for example, or to provide a stopping condition.
Consider the following (C++) code:
// interface for accessing some mesh container int ConnectionsFrom(const cPolyMesh& mesh, size_t f); size_t ConnectionFrom(const cPolyMesh& mesh, size_t f, int i); void AddItemsInFace( const cPolyMesh& mesh, size_t f, std::vector<int>& addTo ); // the algorithm we're interested in void GetReachableItems( const cPolyMesh& mesh, size_t startFace, std::vector<int>& appendTo ) { std::vector<bool> faceReached(mesh.faceSize(), false); std::vector<size_t> facesToExpand(1, startFace); faceReached[startFace] = true; do { size_t toExpand = facesToExpand.back(); facesToExpand.pop_back(); AddItemsInFace(mesh, toExpand, appendTo); for(int j = 0; j != ConnectionsFrom(mesh, toExpand); ++j) { size_t connectedFace = ConnectionFrom(mesh, toExpand, j); if(faceReached[connectedFace]) { continue; } facesToExpand.push_back(connectedFace); faceReached[connectedFace] = true; } } while(!facesToExpand.empty()); }
(Sometimes you need to be careful with vectors of bool, but in this case we're not bothered by the tricky details of this container, so it's just a convenient way for us to set up a bit vector.)
So, we're following connections through some kind of mesh data structure, in a kind of flood fill operation, and returning all the items reached in this way. Let's call this a 'flood' operation, since we'll be using the term 'fill' to mean something else.
This is a made up example, for simplicity, but based on some real life requirements in PathEngine.
Avoiding memory allocations
From an optimisation point of view the first problem here is that this will trigger memory allocations every time it's called. In most situations I'd expect the performance overhead for these allocations to then be the most significant performance issue with this code.
I talked about this a bit in my first post in this series (under 'Run-time dynamic buffers'), and one solution can be to reuse vectors across queries. In this specific case we could do that by changing GetReachableItems() as follows:
#include <cstddef> #include <vector> using std::size_t; class cGetReachableItems_Context { public: cGetReachableItems_Context(size_t meshFaceSize) { faceReached.reserve(meshFaceSize); facesToExpand.reserve(meshFaceSize); } std::vector<bool> faceReached; std::vector<size_t> facesToExpand; }; void GetReachableItems( cGetReachableItems_Context& context, const cPolyMesh& mesh, size_t startFace, std::vector<int>& appendTo ) { // initialise all flags to false context.faceReached.resize(mesh.faceSize(), false); // do the flood fill context.facesToExpand.push_back(startFace); context.faceReached[startFace] = true; do { size_t toExpand = context.facesToExpand.back(); context.facesToExpand.pop_back(); AddItemsInFace(mesh, toExpand, appendTo); for(int j = 0; j != ConnectionsFrom(mesh, toExpand); ++j) { size_t connectedFace = ConnectionFrom(mesh, toExpand, j); if(context.faceReached[connectedFace]) { continue; } context.facesToExpand.push_back(connectedFace); context.faceReached[connectedFace] = true; } } while(!context.facesToExpand.empty()); // restore context vectors to initial state context.faceReached.clear(); context.facesToExpand.clear(); }
So it's possible to now incur allocation overhead just once, on creation of the context object, and then make a whole bunch of subsequent queries that reuse this context object to avoid any further memory allocation.
The code's a bit scruffy. You might want to refactor this a bit around that context class, or you might want to look at making some kind of generalised mechanism for this kind of buffer reuse, but let's assume that is sufficient to resolve the memory issue for our use case, and this'll do, then, as a motivating example for the purposes of this post.
Filling memory
What we're interested in now is the resize call right at the top of GetReachableItems().
Memory is already reserved for the faceReached vector, so what we're doing here is effectively just setting all flag entries back to false. In other words it's a memory fill operation.
Large mesh, small flood
In many cases the cost of this fill operation won't be very significant, but this depends on the exact calling context.
In some cases it's possible that a client wants to use our code with very large mesh objects.
And it's possible also that the only flood operations actually required by this client are all very local to the start face, so that each flood operation only actually ever propagates through a very small part of the mesh.
In these cases the logic for the flood operation itself may not take any time at all, and the flag vector fill can then easily become the main performance bottle-neck.
Cache effects
Note that in addition to time spent directly by the processor writing to memory, the actual overhead for this fill will also include cache effects resulting from the need to writing through all the memory locations covered by the flag vector.
There's a good post about cache effects here (although not specifically in relation to buffer fills).
As a general principle it's just good to avoid going to memory whenever this can be avoided, write accesses are worse than read accesses, and it will be great to remove a whole bunch of unnecessary memory write accesses when and if this is possible.
Attempted solution - keep track of set flags
A first solution could be to record the flags actually set by each query, in a separate buffer, and to only clear these specific entries in our flag vector after the query has completed.
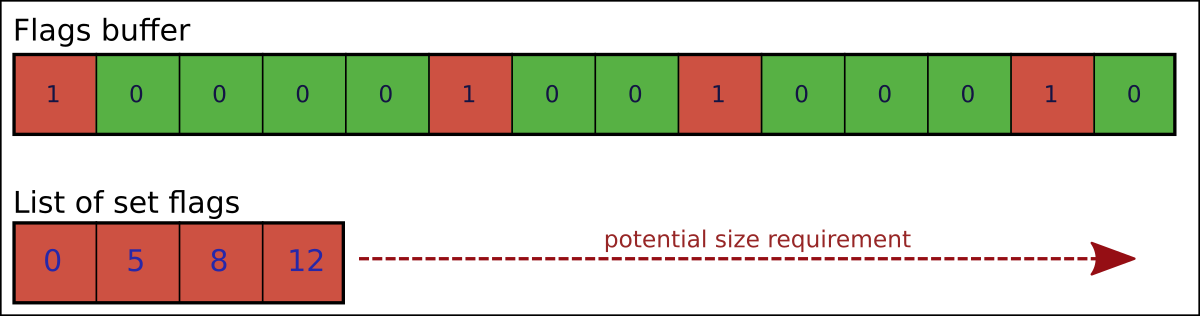
This can work well in specific cases where only a small number of flags are written, but in general we can't depend on this being the case.
For the flood operation the worst case is now the case where the flood does need to traverse a significant portion of the mesh.
And in order to ensure that we have buffers large enough for all cases (to avoid triggering additional memory allocations), we'll need to preallocate the list of set flags to the same size as our flags buffer.
But worse than that, when we come to reset the flags we also now find ourselves having to make a bunch of scattered memory writes. Processors are optimised for sequential writes through a buffer, and if we end up replacing sequential writes throught the whole buffer with scattered writes through most of the buffer then this can end up taking a lot longer than the original fill.
If we know in advance how many flags are likely to be set, perhaps we could implement multiple versions of our bit vector fill strategy, and select a suitable strategy for each query, but in general we don't know what's going to happen in advance (or don't know this easily).
Fortunately, as it turns out, there's a simple way for us to improve on this situation with just one single bit vector implementation!
'Rolling' bit vectors
The solution is to change the way we store our flags, and add some additional state information.
We'll replace our std::vector<bool>
with one integer value per flag entry, and one extra integer that represents a kind of 'rolling' threshold.
The per-entry values will be kept less than or equal to the current threshold (this is a class invariant), and each flag entry then evaluates to true if its integer value is exactly equal to the current threshold, otherwise false.
When we want to set an individual flag we can do this by setting the corresponding integer value to exactly the current threshold.
And now, when we want to clear all currently set bits, we can do this just by incrementing the threshold.
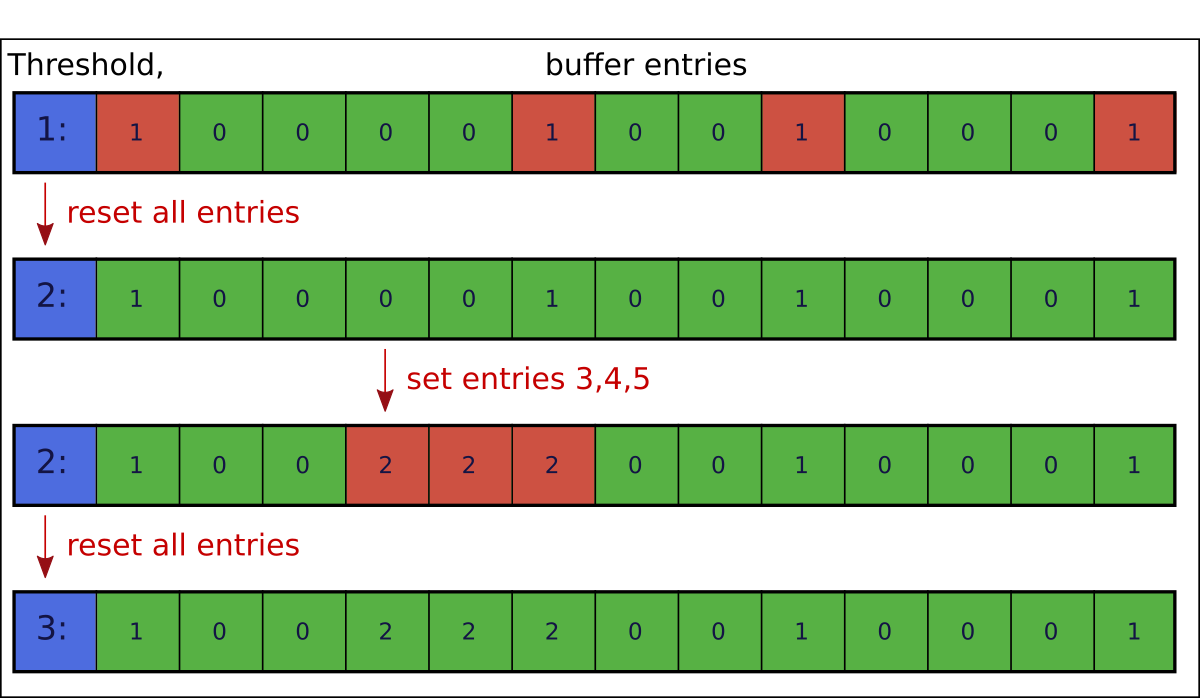
We can make a minimal implementation of this as a C++ class, as follows:
#include <cstddef> #include <cstdint> #include <vector> using std::size_t; using std::uint16_t; class cFastResetBitVector { std::vector<uint16_t> _v; uint16_t _threshold; bool isSet(size_t i) const { return _v[i] == _threshold; } public: cFastResetBitVector(size_t size, bool initialiser) : _v(size, initialiser ? 1 : 0) { _threshold = 1; } bool operator[](size_t i) const { return isSet(i); } void setBit(size_t i, bool value) { _v[i] = value ? _threshold : 0; } void resetAllBitsToFalse() { if(_threshold == 0xffff) { for(size_t i = 0; i != _v.size(); ++i) { _v[i] = 0; } _threshold = 0; } ++_threshold; } };
Note that we have to check for the case where the threshold value is about to overflow, and after 65535 cheap reset operations a 'full' reset is required.
We can update our flood fill code to use this as follows:
class cGetReachableItems_Context { public: cGetReachableItems_Context(size_t meshFaceSize) : faceReached(meshFaceSize, false) { facesToExpand.reserve(meshFaceSize); } cFastResetBitVector faceReached; std::vector<size_t> facesToExpand; }; void GetReachableItems( cGetReachableItems_Context& context, const cPolyMesh& mesh, size_t startFace, std::vector<int>& appendTo ) { // do the flood fill context.facesToExpand.push_back(startFace); context.faceReached.setBit(startFace, true); do { size_t toExpand = context.facesToExpand.back(); context.facesToExpand.pop_back(); AddItemsInFace(mesh, toExpand, appendTo); for(int j = 0; j != ConnectionsFrom(mesh, toExpand); ++j) { size_t connectedFace = ConnectionFrom(mesh, toExpand, j); if(context.faceReached[connectedFace]) { continue; } context.facesToExpand.push_back(connectedFace); context.faceReached.setBit(connectedFace, true); } } while(!context.facesToExpand.empty()); // restore context vectors to initial state context.faceReached.resetAllBitsToFalse(); context.facesToExpand.clear(); }
Note that we implemented an explicit setBit() operation here, and a const indexing operator.
To reduce the need for changes to the calling code we could also consider returning some kind of proxy object.
(std::vector<bool> does this.)
Memory tradeoff
There's one obvious tradeoff here, in that cFastResetBitVector is going to use about 16 times more memory than our original std:vector<bool>
(which will be implemented internally as a packed bit vector, with one single bit per entry).
You could mitigate this to some extent by switching uint16_t to uint8_t, i.e. by storing less bits per flag entry, but you end up falling back to a full buffer reset a lot more often, and in our case the performance benefits were quite significant more than worth the extra memory footprint.
You could also consider switching up from uint16_t to uint32_t, since there are some potential performance hits for using 16 but integers. but in practice, when benchmarking for our use case, uint16_t turned out to be faster.
No big O benefits
One interesting thing to note about this optimisation is that it's kind of an extreme example of how 'big O' complexity measures can potentially be misleading.
Fill operations have exactly the same big O complexity before and after optimisation, i.e. the cost for this is O(n) operation in each case, because the optimisation effectively divides the average cost for the fill by a (quite large) constant factor independently of the number of elements.
(Not saying that complexity analysis isn't important. It is, but just not the whole picture.)
Filling out cFastResetBitVector
I've only shown a very minimal implementation of cFastResetBitVector here, to keep things simple, but
it's pretty straightforward to fill out this class to provide a much more complete drop in replacement for std::vector<bool>.
Actual use cases
We do do some flood fill type operations in PathEngine, but this is not actually our most common use-case for this container.
The most common use case is for keeping track of which elements have already been processed when traversing through partitioned sets of collision elements, where each collision element can potentially be referenced in multiple locations in the partitioning.
Conclusion
It seems like it's quite a common requirement to flag entries in a fixed size set of elements, starting out with all flags unset. If you're using a bit vector for something like this (and you've already resolved memory allocation bottlenecks) try switching the bit vector out for something like cFastResetBitVector!
Updates
- Here's another related data structure that takes this kind of implicit evaluation idea a bit further, for a true 0(1) clear, and fast iteration over the currently set elements, at the cost of larger memory footprint and a more expensive flag test conditional. (Thanks to Fabian Geisen for this link.)
- Some discussion about this post, on reddit
- The idea about 'bucketing' in that reddit discussion is pretty good. The basic idea is to share the integer values between multiple entries, and then if we choose something like 32 or 64 bits per 'bucket', and pack bits into machine words, we end up with something like a more traditional bit vector implementation but with integer values to be compared against a threshold per machine word.
- A related Stack Overflow question (also linked to from the reddit discussion)
- There's an idea about avoiding the need for full clear on threshold overflow on that Stack Overflow page, a bit lost in the comments. This looks like it should work, and give us some additional benefits, although I haven't actually tested this.
Comments (discussion closed)
Cool writeup. I used a similar method back on Bioshock 1 back when we used a... *shudder*... waypoint graph. Rather than resetting all the waypoints to initial values prior to a pathfind, I would use a search index to determine whether we needed to reset the waypoints. Since there were a large number of waypoints and memory on consoles always seems to be scarce, a byte sufficed for the index.
Cheers John! And it turns out there are also a bunch of ways to improve on this that I wasn't aware of. (Check the updates at the end of the main article.)