Automatic Object Linkage, with Include Graphs
(Source code sharing without static libraries)
In this post I describe an alternative approach to sharing source code elements between multiple build targets.
It's based on a custom build process I implemented at PathEngine for our C and C++ code-base (but the core ideas could also be relevant to other languages with compilation to object files).
We'll need to enforce some constraints on the way the source code is set up, notably with regards to header file organisation, but can then automatically determine what to include in the link operation for each build target, based on a graph of include relationships extracted from the source files.
The resulting dynamic, fine grained, object-file centric approach to code sharing avoids the need for problematic static library decomposition, and the associated 'false dependencies'.
Motivation
We need to work with a bunch of different build targets, at PathEngine. There's a run-time pathfinding dll, for example, but also a 3D content processing dll, a 3D testbed application, and so on, with a lot of source code shared between these different targets.
The code was originally split into a set of (internal) static libraries, for this purpose. based on things like theme (e.g. 'Geometry.lib') or application layer ('PathEngine_Core.lib', 'PathEngine_Interface.lib'). Different targets could then share common source code by sharing these static libraries.
This worked, as far as it goes, but something didn't feel right.
The libraries weren't particularly modular, for one thing, and just felt like big old bags of object files that didn't really reflect the actual structure of the underlying code.
A bigger problem was that, for any kind of prototyping work, I ended up having to link in a big chunk of the PathEngine source code, even where only some small part of this was really required. Unit testing was also difficult to setup, for a similar reason.
Since throwing out the static libraries and switching to an alternative approach (as described in this post), prototyping and unit testing tasks are a pleasure, with minimal dependencies and short turnaround times, and project setup is more dynamic and does a much better job of reflecting actual code structure.
Code sharing
In this previous post, I argued against splitting large projects into static libraries.
The key points in that post were:
-
static libraries are little more than archived collections of object files
-
linking object files into static libraries doesn't hide much information, or enforce modularity
-
grouping objects into static libraries adds 'false dependencies', in that linking with one of the objects then requires the whole library
I ended up glossing over an important point in that post, though, I think.
The thing is, static libraries serve another, more basic, purpose, in providing a way to compile some set of source files just once and then share the result between multiple projects.
Regardless of the problems with static libraries, a lot of people still need to use them, if just for this reason.
This post describes another way to share code between build targets, then, without the false dependency problem associated with static library groupings.
Disclaimer: some idealism here, potentially difficult to apply in practice
Personally, I'd like to see the approach described here supported by all of the major C++ build tools and IDEs, but this is not the current reality.
A lot of existing build tools and IDEs seem to be built fundamentally around static library decomposition as the basic tool for sharing objects, this is unlikely to change any time soon.
Switching to the new approach at PathEngine required source code changes throughout the code base, and the implementation of a custom build system, and you have to be something of an idealist to take this path, or at least ready to forgo some of the comforts and benefits of mainstream IDEs.
Starting with a single project
The whole thing really only makes sense where code is shared between multiple projects, but, for simplicity, we'll begin by looking at a single, simple project (an imaginary game application) before extending this to add some additional targets.
We'll start by looking at how compilation dependencies are automated in existing build systems, and then think about how this can be extended, based on certain constraints, to linker dependencies as well.
Compilation dependencies
If I make a change to one of the files in a project, and then rebuild, I don't want to wait while all source files in the project get recompiled. The build system should know something about the set of compiled objects potentially affected by the change, and recompile only those objects.
Let's think about how this works.
Consider some source files that make up our game application:

I've added black arrows for each header file included directly by 'game_main.cpp', and then green arrows for other headers brought in by those headers. Taken together, I'll call this the 'include graph' for this source file.
(For clarity, I'll use the term 'source file', in this post, to refer specifically to files like 'game_main.cpp' that get compiled into objects, and just plain 'file' if I want to include 'source files' and headers.)
If any file reachable through the include graph for 'game_main.cpp' gets modified, 'game_main.obj' may be out of date, and should be recompiled.
Files not reachable through this graph (such as 'graphics_util.cpp') have no effect on the compilation of 'game_main.cpp', and these other files can be changed without 'game_main.cpp' needing to be recompiled.
Include graph generation is probably taken care of transparently behind the scenes, by your IDE, but there are tools for extracting this information, and this is something we'll come back and look at in more detail, later on.
Linker dependencies
What about when we come to link the object files together into a final executable? How does the build system know which object files are required by the link operation?
For our imaginary game application the answer is pretty simple. The source files are there for a reason, they're presumably all needed, and should all be compiled and linked in to the final executable.
(This is how IDEs tend to work, btw.)
But what if these source files were mixed in with a bunch of other source files. Is there some way to automatically determine a set of objects to link?
Inferring link requirements from included headers
Consider one of our headers, 'draw_player.h'. This might look something like the following:
// draw_player.h class IRenderer; class CPlayerState; void DrawPlayer(const IRenderer& render, const CPlayerState& playerState);
This header tells the compiler how DrawPlayer() should be called, with the actual implementation of DrawPlayer() (hopefully) provided in 'draw_player.cpp'.
The information in the header is sufficient for the compiler to generate calling code (setting up the stack set with relevant parameters and making the call), but the actual compiled code for the implementation of function, and the location of the call target, will need to be resolved at link time, by linking with 'draw_player.obj'.
The same is true for headers with class method declarations, as in the following:
// player_state.h class CPlayerState { //... load of private stuff public: CPlayerState(const char* name); int GetHealth() const; //... load of other stuff }
Again, both the constructor and the GetHealth() method shown here need to be implemented in 'player_state.cpp', and resolved at link time by linking with 'player_state.obj'.
In each case there's a matched pair of files with one header and one source file ('draw_player.h'/'draw_player.cpp', 'player_state.h'/'player_state.cpp'), and using stuff in the header creates a link dependency on the corresponding cpp file.
If you look at other C++ features, such as static class data members, you'll see that this works exactly the same way, and, the way I see it, this is really just the way headers are supposed to be used, in C and C++.
Taking one step back, to use stuff in the header you have to include that header. Also, source files should ideally only include headers that they actually use.
So what we're going to do is, wherever a header has a matching source file, and something includes the header, infer a linkage requirement to that source file.
We'll come back and look at the implications of this later on, but first let's see what this buys us.
Adding linkage requirements to the dependencies graph
Adding our new, inferred, linkage requirements in to the dependency graph for 'game_main.cpp' gives us the following:

The idea here is that all the cpp files reachable through this graph are required in order to satisfy potential link requirements in 'game_main.cpp'.
And again, recursively..
Linking with this set of objects is not sufficient, however. Each object brought in to the link has its own dependencies to be satisfied, as well.
To satisfy all the link dependencies for our project, we have to generate include graphs for each new object, recursively, expanding our linkage dependency graph as we go.
We could expand 'world_update.cpp' next, for example, with the expansion looking like this:

As before, black arrows and green arrows indicate the include graph for the object being expanded, and red arrows show inferred linkage. I've added yellow arrows to show the linkage dependency graph built up so far.
Some of the dependencies of 'world_update.cpp' are already in our linkage graph, and no further action is required for these source files, but 'enemy_ai.cpp' is new, and we'll add this.
I won't show all of the source file expansions, but if we continue expanding new source files we'll eventually satisfy all linkage requirements, at which point we have a complete set of source files to compile and link into an application.
In our case the last required source file, 'graphics_util.cpp' gets added (for example) when expanding the subgraph for 'draw_player.cpp':
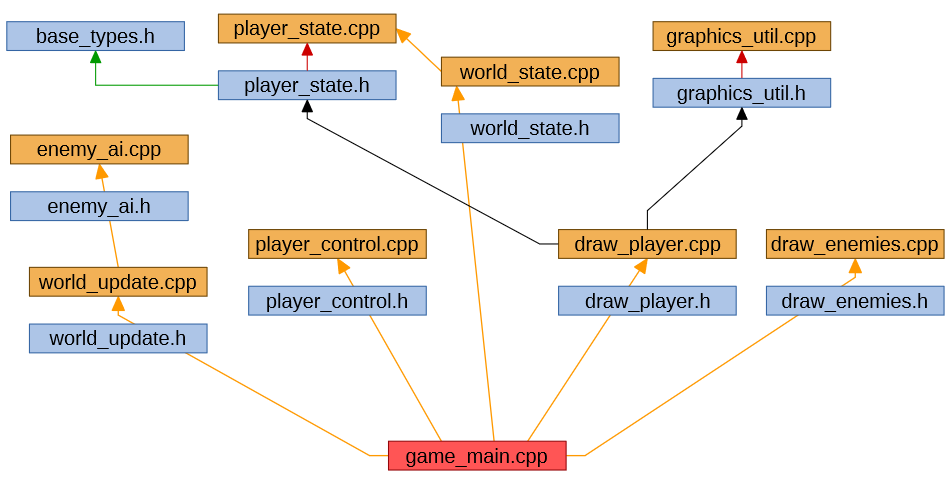
What does this give us?
This may seem like a lot of messing around for our simple game application, where linkage requirements are obvious, but starts to make more sense if we add some additional targets.
Let's make this into a networked game, then. We'll split the code into two applications, one for the game server, and another for the game client.
Each application is defined by a single root source file, and expanding linkage requirements our from root source files gives us the set of source files actually needed to satisfy linkage requirements for each application.
For the server, this works out as follows:
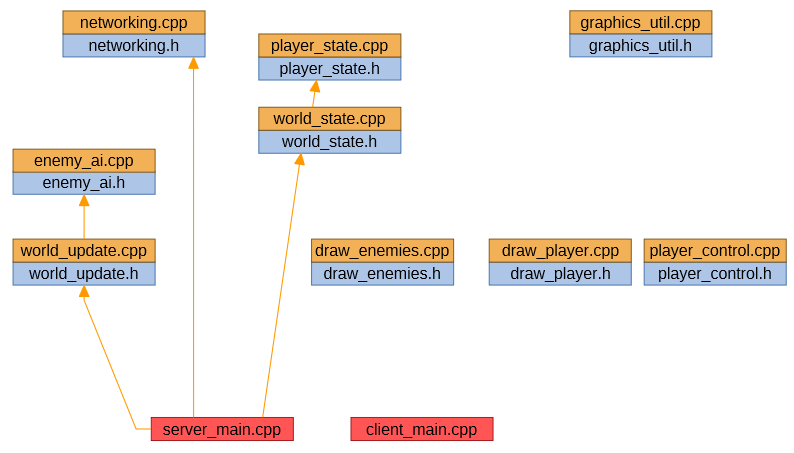
For simplicity, I've removed the 'base_types' header (which doesn't actually have any effect on linkage requirements), and combined source/header pairs into single nodes (effectively collapsing those red arrows).
A new source file, 'networking.cpp', is used to pass serialised information about world state over the network. The server just updates the world, and runs the enemy AI, but doesn't handle player input or rendering.
The linkage dependencies for our client application are generated from the same source tree, and look like this:
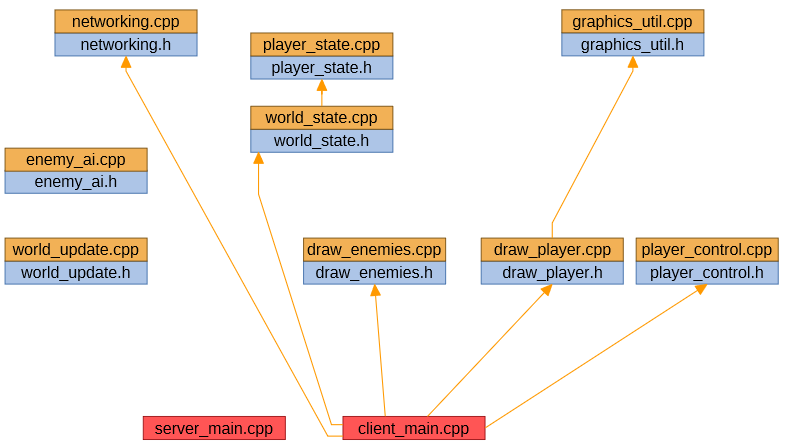
The first advantage of the PathEngine build system, then, is automatic generation of the set of objects to link for each build target.
This avoids work setting up and maintaining lists of objects in application projects and shared libraries, and dependencies between those projects.
Eliminating manual project configuration elements eliminates the possibility of human error in the way these project configuration elements are setup.
Automated dependencies also makes the source code more dynamic and easier to refactor, since we can change relationships between source code elements directly in the source code, without worrying about the need to wrestle with project setup (even for changes with significant implications for dependencies).
That's all good stuff, but there are other advantages of this set up, which brings us to the second key feature of the PathEngine custom build system, object sharing.
Shared object files
We can see from the diagrams above that some of the objects ('networking.cpp', 'player_state.cpp' and 'world_state.cpp') are used by both server and client.
With our custom build system, the corresponding object files ('networking.obj', 'player_state.obj' and 'world_state.obj') are then shared by the two applications. If I build the server, and then the client, these object files are generated only once, and then get reused.
There are some implications of this setup. You can't set different compiler settings for a given source file for different targets, and this means you can't use constructs like the following:
// in networking.h #ifdef BUILDING_CLIENT //... some logic #endif #ifdef BUILDING_SERVER //... some other logic #endif
This is the same situation as for objects in a static library, however, and you can kind of think of each object file as being its own mini static library.
In practice I prefer to avoid this kind of construct. I think source files that 'compile only one way' are easier to understand, and in return we get the significant benefit (as with code sharing through static libraries) of avoiding recompilation, hence faster build times.
Unit tests
I mentioned unit testing as one of the benefits of the new approach. Lets see how this looks for our game source code.
Well, each unit test is essentially just another 'root source file' for which a set of linker dependencies can be determined.
Isolating individual unit tests
When the source file under test is mostly independent from other source files, we get a nice minimal set of objects to build:
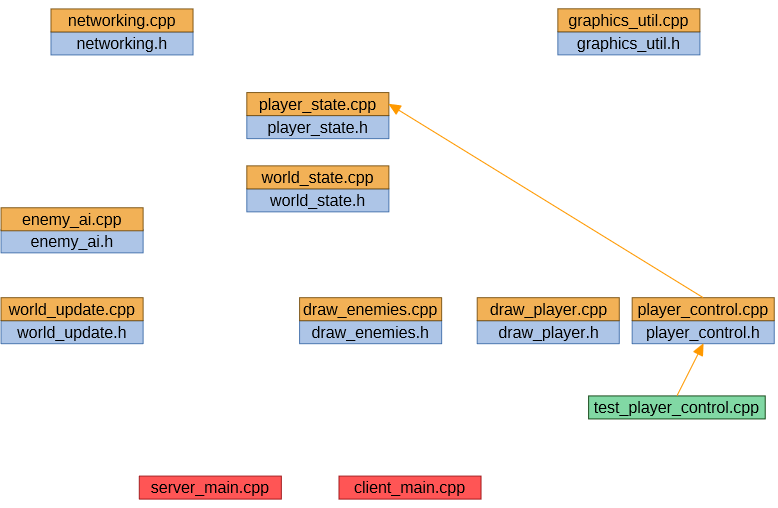
Being able to build and run just a single test, with low turnaround times, is great for iterating on initial test set up, when adding regression, and when debugging the test to fix a complicated issue, and it's great to be able to run individual unit tests when other bits of source code are broken for some reason.
A minimal working set, with less code linked into a test binary, also means less chance of side effects from other code and less mental load, with less things potentially needing to be considered.
Grouping unit test together
A lot of the time you probably just want to verify that the tests all still pass, and building an individual exe for each unit test would then be overkill.
The trick, in this case, is to start the dependency analysis with more than one root source file and build multiple tests into a single executable.
The PathEngine build system does this for sets of tests matching a regular expression, omitting tests which have already passed and are unaffected by source code changes, (but full details about how to set this up are beyond the scope of this blog post).
Higher level testing
We can apply the same principle, also, to less 'independent' source files, and end up with a kind of mid-level test:

Working with the same compiled result
In each of these testing use-cases, compiled objects are shared with the main application, and we're testing exactly the same compiled code as gets linked into our production application.
This avoids situations, notably, where an issue is caused by a compiler bug, or only repeats when code is compiled a certain way, but doesn't repeat when the code is compiled differently for testing.
Source file organisation is often orthogonal to dependency
When I set up static libs for PathEngine based on theme or application layer, this turned out to be a bad way to manage dependencies, but that doesn't mean that these are inherently bad ways to organise source code.
Let's take one more look at our networked game source code:
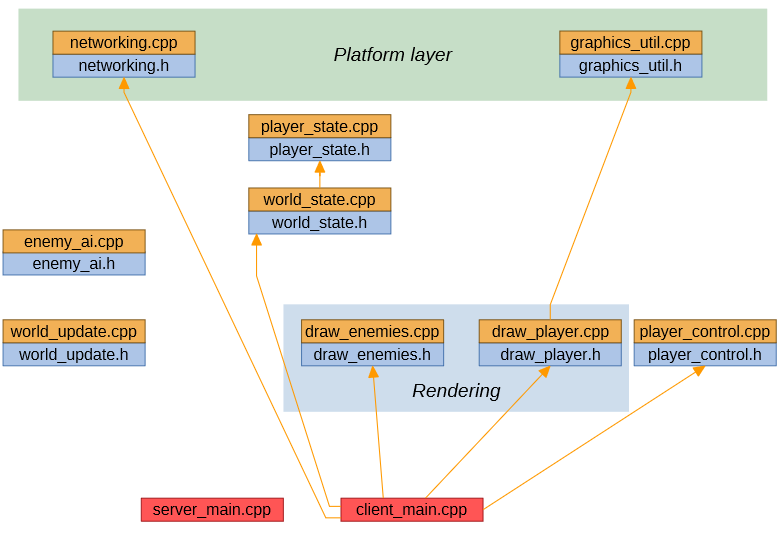
Grouping by layer
A couple of source files are different in that they don't know anything about the specific application domain of our game, and I'm going to call this group of files 'the platform layer'. These files can go in a separate, suitably named, top-level directory from the rest of the source code.
I'd also like to add a constraint that code in the platform layer should never include or call into lower 'application' layers.
This seems like it can be a useful way to group source files, but that doesn't mean that the code should also be clumped together into a single dependency unit. Forcing the game server to link with 'graphics_util.h' certainly seems like a bad idea. (Maybe this adds a dependency on DirectX, and the relevant runtime is not installed on the server machine..)
Grouping by theme
Another two files both share the common feature of drawing something. Grouping these files into the same 'Rendering' subdirectory also seems like a good idea.
We may turn out to need other things rendered, and so other similarly themed source files are likely to get added, as our application grows. It will be nice to able to locate these files quickly, and to get an idea about what kinds of different things our source code is currently able to render, but there's no reason to think that code that wants to draw one thing (e.g. the player) will always also want to draw everything else.
Separating these source file groupings out from project dependency structure also has the effect of making the grouping more dynamic. If one of these groupings turns out not to make so much sense later on, it's great to be able to change these groupings without subsequently wrestling with dependency implications to make everything work once again.
Inferring link requirements, what could go wrong?
I've hopefully shown, at this point, that automatic object linkage is nice to have, but our implementation of this is based on some assumptions about the source code.
Specifically, we're assuming that source files and headers are always set up as matching pairs, that code does not 'bypass' headers and declare linkage directly, that headers actually do contain elements that require linkage to the corresponding source file, and that source code that includes the headers actually does use these elements from the headers.
None of this is guaranteed by the standard. What could go wrong?
Well, just two things, essentially:
- Linking not enough objects
- Linking too many objects
Bypassing a header
Instead of including 'draw_player.h', someone might do the following:
// in game_main.h void DrawPlayer(const IRenderer& render, const CPlayerState& playerState); int main(int argc, char* argv[]) { //... set up renderer //... set up world and player state //... other stuff DrawPlayer(renderer, playerState); //... other stuff }
What happens?
Nothing includes "draw_player.h", we fail to detect the linkage requirement, "draw_player.cpp" is not compiled or linked in, and we get a link error as follows:
game_main.obj : error LNK2019: unresolved external symbol "void __cdecl DrawPlayer(class IRenderer const &,class CPlayerState const &)" (?DrawPlayer@@YAXAEBVIRenderer@@AEBVCPlayerState@@@Z) referenced in function main
Well, first of all, I don't want anyone to write code like this. There's a reason for the header. Bypassing the header makes the code brittle with respect to changes to the DrawPlayer() function signature, but also makes it harder to identify code that uses rendering functions (by searching for include lines), and this is a code quality issue that I'm happy to see identified by an error.
But the point is, even with code like this, the result is far from catastrophic. It's the same error as if you forget to add a new cpp file to a Visual Studio project, with standard project, but less likely to happen, and with the same kind of direct line back from error to cause.
Global linkage requirements
Another way we might miss linkage requirements is due to the kind of 'global' linkage requirement implied by something like the following:
// abbreviated version of "Assert.h", from PathEngine #pragma once extern "C" { int PathEngine_HandleAssertion(const char*, int32_t, const char*); } #define assertR(expr) do{static int on = true;if(on && !(expr)) on = PathEngine_HandleAssertion(__FILE__,__LINE__,#expr);}while(0) #ifdef ASSERTIONS_ON #define assertD(expr) assertR(expr) #else #define assertD(expr) do{}while(0) #endif
In this case, there is no single corresponding "Assert.cpp". Instead, different types of application are expected to provide suitable implementations of PathEngine_HandleAssertion(), depending on the desired behaviour. (In some cases a message box should pop up. In others, assertions should be printed to console output, or logged. Sometimes it should be possible to turn assertions off, and so on.)
But what if I want to share common assertion handling strategies between applications?
I can set up a source file "MessageBoxAssert.cpp", for example, but no header is required for this (with PathEngine_HandleAssertion already declared in "Assert.h"). Because there is no matching header pair, nothing tells the build system that this source file needs to be compiled, or that "MessageBoxAssert.obj" needs to be included in the link.
There are perhaps better ways to handle this kind of situation, but what we do currently in PathEngine, is go ahead and add an empty "MessageBoxAssert.h", anyway. This (empty) header file can be included from the relevant application root source file just to indicate that linkage to "MessageBoxAssert.cpp" is desired.
Linking objects that aren't required
Consider the following class:
// position.h class CSerialiser; class CPosition { int x; int y; public: CPosition(int x, int y) : x(x), y(y) { } int getX() const { return x; } int getY() const { return y; } void translateBy(int dx, int dy) { x += dx; y += dy; } void serialise(CSerialiser& s) const; };
Not a hugely useful class, but the point is that nearly everything here is implemented inline in the class header.
There is a matching "position.cpp", however, containing just the definition of CPosition::serialise().
Perhaps I have some code that needs to do some stuff with positions, but doesn't need to serialise them.
Due to the way we infer linkage dependencies, "position.cpp" will get pulled in to the link, as well as "serialiser.cpp" (and probably whole a bunch of other stuff) even if none of this is actually used.
Note that I haven't seen this issue in PathEngine, in practice, and this is really just a theoretical objection to inferring linkage requirements the way we do.
I guess the point is that, although the method we are using for inferring linkage dependencies is more fine grained than and relationships between static libraries, in some cases it may not be fine grained enough.
And I guess the answer is then that, sure, the approach is not perfect but it's nevertheless a significant improvement on what we had before, and also turns out to be a good fit for a bunch of situations, in practice.
Perhaps it's possible to go further and analyse each source file to determine whether there actually are declarations brought in from headers, without associated definitions, but that would be a big increase in complexity, and I don't think this is necessary.
It's probably better to change the code in some way, so that the relevant dependency is explicit in the source code include relationships.
For this position class, one possibility would be to pull the serialisation operation out of the class and express this in terms of externally visible methods, and another would be to hide the implementation details of the serialiser behind a virtual interface.
Setting up a tool to answer queries about why specific objects are included in a link operation, by reporting the relevant linkage chain, can help a lot with this.
Extracting includes from source files
Let's come back and take a look, finally, at the process of extracting the relevant include graph information from our source files.
The simplest way to do this, these days, is probably just to use a compiler option that tells your compiler to do this.
In the case of gcc (and clang) you can use the -M (or -MM) compiler option (see this page, in the docs). For the Microsoft Visual C++ compiler there's /showIncludes.
Using the compiler to do this makes sense because the process of extracting includes is a subset of the compile task itself.
Notably, for each source file analysed in this way, each included header needs to be loaded in from disk, and examined in the specific preprocessor context at that point in the compile.
And this means that, when iterating over the set of all source files, certain commonly included headers may end up being loaded and examined many times over.
To illustrate exactly why this is necessary, consider the following (made up) example:
// commonly_included_header.h #include "base_stuff.h" #ifdef MESSAGE_BOXES #include "message_box_errors.h" #else #include "console_errors.h" #endif //.. bunch of other stuff
This potentially results in a different set of includes, depending on the state of the REPORT_ERRORS define, which may be different for different source files, depending or how it is set in the source file itself, and whether it was set or unset by previously included header files.
If it wasn't possible for preprocessor conditionals to affect include directives, we could analyse each header individually, and re-use the results wherever the header is included.
But these kinds of preprocessor conditionals are also pretty confusing, in my opinion, and make the code harder to work with.
What we do in PathEngine, then, is straight-out disallow conditional compilation around include directives. The mechanism for this is pretty straightforward. Include directives are only allowed right at the top of each header, with no other preprocessor statements allowed before or between the include directives.
This might seem like quite a significant source code constraint. Conditional include directives sometimes seem like they are indispensable, particularly when you are building for a lot of different platforms.
In my experience, however, we don't have to set things up this way. Preprocessor conditionals like this should usually be set consistently across builds, and can then be replaced by the alternative mechanism of include directory search order:
// commonly_included_header.h #include "base_stuff.h" // the following might include either // "message_box/errors.h" // or // "console/errors.h" // depending on include directory search order #include "errors.h" #endif
With this constraint in place, the resulting 'per header' approach to includes analysis gives us two very significant speedups:
- Each header is loaded and processed only once, so fewer files are loaded and processed in total (potentially a change from O(n^2) to O(n), I think, depending on include graph branching factor).
- After one header is edited, only that header needs to be re-processed, and no others (as opposed to all dependent files).
Interacting with IDEs
For PathEngine, switching to the approach I have described meant implementing a custom build system, but that doesn't mean we have to go right back to the stone age, or implement our own IDE from scratch.
There are a couple of ways our custom build system can interact with modern IDEs.
External build projects
Most IDEs offer some kind of 'external build' project setup where you can specify an arbitrary build command, and have build output directed into the standard build output window.
It's usually straightforward from there to set up filtering for errors, so that 'go to next error' functionality can be used, and to run and debug your build result.
After that this approach can offer a lot of the benefits of the custom build system, such as object file sharing, implicit build targets, and unit testing, but at the expensive of features like intellisense, which depend on the IDE understanding exactly how to build your code.
(I've implemented a libClang based 'lookup reference' feature for an external project setup, and found that I can be quite productive with this kind of minimal 'intellisense', but it's a far cry from all the bells and whistles of a something like Visual Studio, and certainly not for everyone.)
Generated project files
The second possibility is to make your build system spit out standard project files for individual targets, for your IDE, when required.
Actually, the main thing we want from the build system is the list of source files to be included for the relevant target, and project files can then generated from templates and filled out with these source files.
The project won't update dynamically to reflect changes to include relationships, but we can get pretty close by triggering a script to regenerate the projects manually, when necessary. (Visual Studio actually handles background changes to projects you are working on quite nicely. A message box pops up asking if you want to reload the projects, and the reload process all seems to be fairly robust.)
The benefit of this kind of setup is that you can take advantage of all those IDE bells and whistles (intellisense, detailed code highlighting, and so on). The disadvantages are that each project file generated in this way can only build one target, and object files are no longer shared between projects.
Juggling the two approaches
Between the two approaches it's possible to do pretty much everything you can do with a modern IDE.
Sometimes I'll switch between the two approaches depending on what platform I'm working on, and what exactly I want to do. If I'm prototyping or unit testing, I prefer to use external build projects (and the full power of our custom build system). If I'm working on a larger application, however, on Windows, a generated Visual Studio project can be a better way to go.
Juggling two types of project files is not ideal, however, and it would be great to combine the advantages of the two approaches into a single integrated setup.
Summing up
With some assumptions about header organisation, we can infer the set of objects required to build an application from just one 'root' source file, and the include relationships implicit in the source code.
The result is a very dynamic approach to project management, which eliminates the need for a lot of manual project configuration, with shared object files, and finer grained dependencies than standard static library decomposition.
We had to add source code constraints to make this work but this works out well in practice and these are arguably good constraints to apply on your source code, anyway.
It's an idealistic approach to project setup, and tricky to reconcile with project configuration options in popular IDEs, but perhaps this is how IDEs should work in the future?
Comments (discussion closed)
Any plans to release your build system?
Yeah, I thought about it. The PathEngine build system is a bit specific to PathEngine, and a bit messy in places. I started out rewriting the core of the build system more generically, in Rust (as an exercise for learning Rust, really). This works as far as it goes, and is nice and fast, but I haven't had the time to really get this to the point where I would be happy to release it. I would also be interested in getting this kind of approach integrated with an IDE, but, well, it doesn't really seem like there is much interest in this kind of setup.
https://www.youtube.com/wat... describes TomTom's build system that automatically generates CMakeLists.txt files by scanning the include relationships in the source, but it still uses static libraries.