Efficient Vectors of Vectors
(Second in a series of posts about Vectors and Vector based containers.)
STL style vectors are convenient because they hide the details of internal buffer management, and present a simplified interface, but sometimes convenience can be a trap!
In my previous post I touched briefly on STL vectors with non-simple element types, and mentioned the 'vector of vectors' construct in particular as a specific source of memory woes.
In this post I'll talk about this construct in more detail, explain a bit about why there is an issue, and go on to suggest a fairly straightforward alternative for many situations.
Interview question
One of my standard interview questions for c++ programmers has been:
What can be done to optimize the following class?
#include <vector> class cLookup { std::vector<std::vector<long> > _v; public: long addLine(const std::vector<long>& entries) { _v.push_back(entries); return _v.size() - 1; } long getNumberOfEntriesInLine(long lineIndex) const { return _v[lineIndex].size(); } long getEntryInLine(long lineIndex, long indexInLine) const { return _v[lineIndex][indexInLine]; } };
(Index type issues ignored for simplicity.)
Note that the question intentionally doesn't tell you what needs to be optimised. I guess I ideally want applicants to then either:
- ask what should be optimised, or
- immediately spot what is 'wrong' with the code (and go on to make some suggestions for improvement)
It's generally a good first reflex in any optimisation situation to try to find out some more about exactly what's going on (whether by profiling, or measuring statistics, or even just looking at how a piece of code is used), and (perhaps more fundamentally), what needs to be optimised, and so asking for more information is probably a good initial response to pretty much any optimisation question.
But the vector of vectors in the above code such an expensive and inefficient construct that if you've ever done something like this in the wild, or come across similar constructs during optimisations, then it should really stand out as a red flag, and I don't think it's unreasonable to just assume that this is what the question is asking about.
The problem
The class methods can be divided into a 'lookup building' part, which might only be used at preprocess or loading time, and a non-mutating 'query' part.
In real life we should usually be motivated and directed by some kind of performance measure, and there are then two issues potentially resulting from that vector of vectors, with our performance measures ideally telling us which (or both) of these issues we actually need to focus on:
- inefficiencies during construction, or
- run-time memory footprint
Lookup construction
The construction part has the potential to be horribly inefficient, depending on the compilation environment.
It's all about what the top level vector does with the contained objects when increasing buffer capacity, and, more specifically, whether or not C++11 'move semantics' are being applied.
To increase buffer capacity, vectors allocate a new block of memory and then move the contents of the existing buffer across. Before C++11 move semantics the move part actually requires copy construction of elements in the new buffer from elements in the old buffer and then destruction of the old elements, but with C++11 move semantics this copy and destroy can be avoided.
We can see this in action with the following test code:
#include <vector> #include <iostream> int i = 0; class cSideEffector { int _i; public: cSideEffector() { _i = i++; std::cout << "element " << _i << " constructed\n"; } cSideEffector(const cSideEffector& rhs) { _i = i++; std::cout << "element " << _i << " copy constructed (from element " << rhs._i << ")\n"; } ~cSideEffector() { std::cout << "element " << _i << " destroyed\n"; } }; int main(int argc, char* argv[]) { std::vector<std::vector<cSideEffector> > v; v.resize(4); v[0].resize(1); v[1].resize(1); v[2].resize(1); v[3].resize(1); std::cout << "before resize(5), v.capacity() = " << v.capacity() << '\n'; v.resize(5); return 0; }
Building this with Clang 3.0, without the -std=c++0x option, I get:
element 0 constructed element 1 copy constructed (from element 0) element 0 destroyed element 2 constructed element 3 copy constructed (from element 2) element 2 destroyed element 4 constructed element 5 copy constructed (from element 4) element 4 destroyed element 6 constructed element 7 copy constructed (from element 6) element 6 destroyed before resize(5), v.capacity() = 4 element 8 copy constructed (from element 1) element 9 copy constructed (from element 3) element 10 copy constructed (from element 5) element 11 copy constructed (from element 7) element 1 destroyed element 3 destroyed element 5 destroyed element 7 destroyed element 8 destroyed element 9 destroyed element 10 destroyed element 11 destroyed
But if I add the -std=c++0x option (enabling C++11 move semantics), I get:
element 0 constructed element 1 constructed element 2 constructed element 3 constructed before resize(5), v.capacity() = 4 element 0 destroyed element 1 destroyed element 2 destroyed element 3 destroyed
So we can see first of all that without move semantics enabled each buffer reallocation triggers copy and delete for all the existing elements. And then we can see that this is something that this is something that can potentially be resolved by turning on support for move semantics.
Note that this copy and delete usually won't be an issue for basic types (where copy can be just a memory copy, and delete a null operation), but if the vector elements have their own internal buffer management (as is the case with vectors of vectors) then this results in a whole lot of essentially unnecessary memory heap operations, which be both a significant performance hit and bad news for memory fragmentation.
Move semantics can be pretty cool if you can depend on the necessary compiler support, and you can then find a load of stuff on the web discussing this in more detail (e.g. here or here).
At PathEngine, however, we need to support clients building the SDK on a bunch older compilers, and if there is some way to implement stuff like this lookup class without all this overhead regardless of whether C++11 move semantics are actually available then we definitely want to do this, and the lookup construction stage remains an optimisation target!
It's all about the runtime
Actually, in practice we would never want to do something like cLookup::addLine() during loading. Something like this would normally only be called at preprocess generation time, with the possibility to store the resulting preprocess data to persistent files and load back in at runtime with much more direct data paths.
(In reality there would be some other stuff to support this in that cLookup class, this is a simplified example and doesn't give the whole picture.)
And then, while we obviously want to avoid all those memory ops during preprocess generation, the real issue here is probably the implications of the vector of vector construct on the SDK run-time, and particular on run-time memory footprint.
It turns out that vectors of vectors are also very bad news for your system memory heap. For something like PathEngine this is worse than the potential construction inefficiencies from unnecessary copying, and this is an issue whether or not C++11 move semantics are being applied.
Memory footprint
From the point of view of memory footprint there are two main problems here:
- The fact that separate buffer allocations are made per entry in _table, and
- Operating system and vector class memory overhead for each of those allocations
The situation will look something like this:
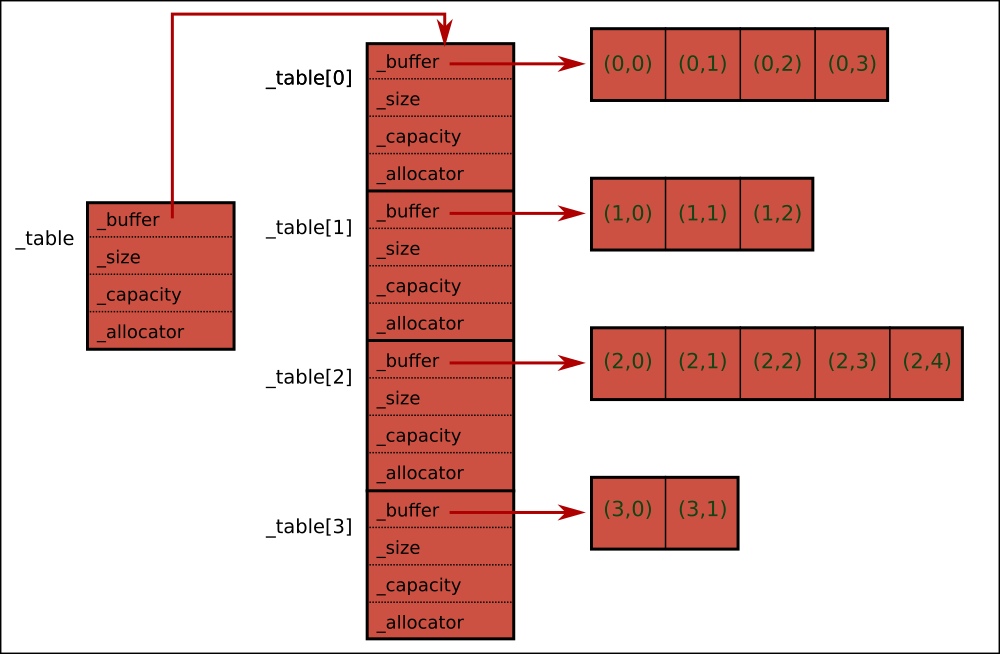
One buffer gets allocated at the top level, by _v, and filled in with the sub vector class data, and a bunch of other buffers then also get allocated by these sub vectors.
Note that each vector has four data members, a buffer pointer, a current size value (or end pointer), a current capactity (or end pointer), and a pointer to an allocator object. It's most common to see STL containers without allocation customisation, and so it can be a surprise to see the allocator pointer. When allocator customisation is not being used the allocator pointers all be set to zero, but nevertheless get stored once per lookup line, and help to bulk out the memory overhead.
If each of the four vector data members is a 32 bit value then this gives us a starting cost of 16 bytes per line in the lookup, most of which is not really necessary in this case.
And allocating an individual buffer for each line is also a bad thing because allocating a lot of buffers will lead to memory fragmentation, and because there is a non-negligeable amount of built in hidden overhead per system memory allocation. Each individual buffer allocated from the system will require additional data related to tracking the buffer in the system memory allocation heap, and will also most likely be aligned to some fixed value by the system (so with memory buffer lengths actually being extended to a multiple of that fixed value).
As a result, for a lookup object created with short lines, the memory overhead for each line can easily exceed the amount of actual data being stored.
And we should also be aware of the possibility of vector overallocation.
In the code shown, the subvectors probably shouldn't be overallocated because they are copy constructed from existing vectors (although I haven't researched the 'official' situation for this in the standard!), but the top level vector will be overallocated (by a factor of 1.5, on average, as discussed in my previous post), and in the general case of vector of vector construction overallocation may not just mean buffers being larger than necessary, but also potentially that more buffers are allocated than actually needed.
In practice, in loading code, we set things up so that vectors get loaded without any overallocation, but it can be worth checking that this is definitely working as expected.
With or without overallocation it's clear that there are some significant memory footprint and fragmentation issues, and these kinds of memory issues are then also usually performance issues, because of the need to keep memory caches working effectively, and because of heap management costs!
Collapsed vector vector
The key point, for this use case, is that we actually only ever need to add data to the end of the lookup, and so we just don't need all that separate dynamic state tracking for each individual line.
And the solution is then to 'collapse' all those individual line buffers into a single buffer, giving us just one single buffer containing all the lookup entries concatenated together in order.
Since the lookup lines are not all the same length we also need some way to find the lookup entries for each line, and so we use a second buffer which indexes into the concatenated entries for this purpose.
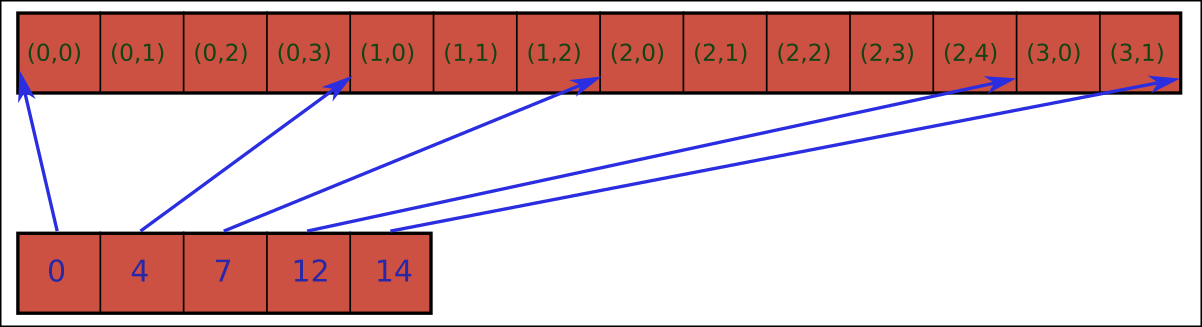
The index buffer tells us exactly where each line starts in the concatenated entries buffer.
Note that we give the index buffer one entry per lookup line, plus one additional entry which points to the end of the concatenated entries. (This extra index entry enables us to treat all the lookup lines in the same way, and avoids an explicit test for first or last line.)
We could add code for this directly into the cLookup class fairly easily, but this is something we're bound to come across with regards other data structures, and we should set things up to make it as easy as possible for us to avoid the vector of vectors construct, so why not create a new container class for this purpose, which can be used to replace vectors of vectors more generally?
Data members
We need to maintain a couple of dynamically resized buffers (with increasing size), and std::vector is actually just the thing for that (!), so we can start out with something like:
#include <vector> template <class T> class cCollapsedVectorVector { typedef typename std::vector<T>::size_type size_type; std::vector<T> _v; std::vector<std::size_type> _index; public: //... implementation here };
These vector members save us re-implementing a bunch of low-level buffer management stuff, whilst still resolving all the major issues we had with the vector of vectors construct.
We want to make it easy to replace vector of vectors with this new class, so lets copy the std::vector interface as far as reasonably possible.
We'll add things like a size_type typedef and basic STL style vector methods like size() and empty(), and try to make common element access code for vectors work with the new class.
We could also provide the same interface for the actual push_back operation (i.e. taking a subvector to be concatenated), but I've chosen to diverge from that interface to make it clear in the calling code that something a bit different is going on at construction time.
I've also avoided trying to do anything that might require proxy objects or iterator classes in order to keep things simple. The final class can then look something like this:
#include <vector> #include <cassert> template <class T> class cCollapsedVectorVector { public: typedef typename std::vector<T>::size_type size_type; private: std::vector<T> _v; std::vector<size_type> _index; public: cCollapsedVectorVector() : _index(1) { _index[0] = 0; } cCollapsedVectorVector(const std::vector<std::vector<T> >& buildFrom) : _index(buildFrom.size() + 1) { _index.clear(); _index.push_back(0); for(size_type i = 0; i != buildFrom.size(); ++i) { _index.push_back(_index.back() + buildFrom[i].size()); } _v.resize(_index.back()); size_type vIndex = 0; for(size_type i = 0; i != buildFrom.size(); ++i) { for(size_type j = 0; j != subVectorSize(i); ++j) { _v[vIndex++] = buildFrom[i][j]; } } assertD(vIndex == SizeL(_v)); } void shrinkToFit() { if(_v.capacity() != _v.size()) { std::vector<T>(_v).swap(_v); } if(_index.capacity() != _index.size()) { std::vector<size_type>(_index).swap(_index); } } bool operator==(const cCollapsedVectorVector& rhs) const { return _index == rhs._index && _v == rhs._v; } void swap(cCollapsedVectorVector& rhs) { _v.swap(rhs._v); _index.swap(rhs._index); } bool empty() const { return _index.size() == 1; } void clear() { _index.resize(1); _v.clear(); } void pushBackSubVector() { _index.push_back(_index.back()); } void pushBackSubVector(size_type size) { _index.push_back(_index.back() + size); _v.resize(_v.size() + size); } void pushBackInLastSubVector(const T& value) { assert(!empty()); _index.back()++; _v.push_back(value); } void popBackInLastSubVector() { assert(!empty()); assert(subVectorSize(size() - 1) > 0); _index.back()--; _v.pop_back(); } size_type size() const { return _index.size() - 1; } const T* operator[](size_type i) const { return &_v[_index[i]]; } T* operator[](size_type i) { return &_v[_index[i]]; } const T* back() const { assert(!empty()); return &_v[_index[_index.size() - 2]]; } T* back() { assert(!empty()); return &_v[_index[_index.size() - 2]]; } size_type subVectorSize(size_type i) const { return _index[i + 1] - _index[i]; } };
Application
In cases where we only need to add to the end of the data structure (as in the case of cLookup), we can build to this new class directly, but in cases where this is not possible we could also fall back to using a vector of vectors at build or preprocess time, with this then baked into a cCollapsedVectorVector using the relevant constructor.
Anyway, now we can rewrite the lookup class as follows:
class cLookup { cCollapsedVectorVector<long> _v; public: long addLine(const std::vector<long>& entries) { _v.pushBackSubVector(entries.size()); for(std::vector<long>::size_type i = 0; i != entries.size(); ++i) { _v.back()[i] = entries[i]; } return _v.size() - 1; } void shrinkToFit() { _v.shrinkToFit(); } long getNumberOfEntriesInLine(long lineIndex) const { return _v.subVectorSize(lineIndex); } long getEntryInLine(long lineIndex, long indexInLine) const { return _v[lineIndex][indexInLine]; } };
Note the addition of a shrinkToFit() method, which can be called when the calling code has finished adding lines, to avoid overallocation.
Conclusion
Vectors of vectors should be avoided if possible, and if data is only ever added at the end if the top level vector this is easy to achieve.
This is an example of an optimisation which should be applied pre-emptively, I think, because of the performance and memory footprint implications.
If you have vectors of vectors in your code, take a look at this right now and see if they can be replaced with something like cCollapsedVectorVector!
Comments (discussion closed)
Interesting article! I'm a little confused though; for this problem we can't depend on having C++11 move semantics but we can depend on having vector::shrink_to_fit()?
You can shrink vectors to fit without C++11, for example with the following external helper method:
Vector of vectors provides more flexibility, than you really need. You do not need ability to insert in the middle, but you pay for it.
I'm not sure if there is a fundamental CS law, but generally for every O (1) insertion point you must pay with memory. Linked list has the most constant time insertion points (everywhere) and the worst memory layout. Deque has two fast insertion points and suffers from suboptimal memory layout (normally vector of vectors).
The apparent lesson here is that not every required data structure is available in standard library. For every set of requirements on complexity of container operators there is a different optimal data structure.
P.S: I wonder if replacing naked loops with std::transform and std::copy makes the code more readable or less readable.
Thanks a lot, I'm going to try this tomorrow to optimize the "open" list of an A* algorithm.
I'm an old-school C++ guy trying to learn STL, 11 (if not newer) etc. Thanks for the interesting reading.
cCollapsedVectorVector() :
_index(1)
{
_index[0] = 0;
}
At first glance this looks like at init time it'd semantically have one empty array in it, whereas vector<vector<long>> has no empty arrays in it?
_index(buildFrom.size() + 1)
{
_index.clear();
_index.push_back(0);
In the second constructor I'm confused why make a big vector, clear it, and add an element?
No problem. But note that the code here is from before we moved up to C++11 (i.e. C++98!). I guess the most significant change moving up to C++11 is the addition of move constructors.
The _index vector always has size + 1 elements. This is so that you can calculate the size of each sub-vector, including the last one, by subtracting _index[i] from _index[i+1].
This is just to ensure the whole buffer is allocated up front, and avoid multiple allocations as _index grows.
It would be better to use a call to reserve() for this, then, but works out much the same in practice..